- 首页
- /
- llm-for-zotero 文档
- 在 GitHub 上查看 ↗
llm-for-zotero:面向 Zotero 文库的研究 Agent 系统




llm-for-zotero 将大型语言模型带入 Zotero 阅读器,让您无需离开文库即可提问、总结论文、解读图表、比较文献并保存笔记。它支持常规 API 服务商、本地 OpenAI 兼容模型、WebChat、Codex App Server 和 Claude Code。
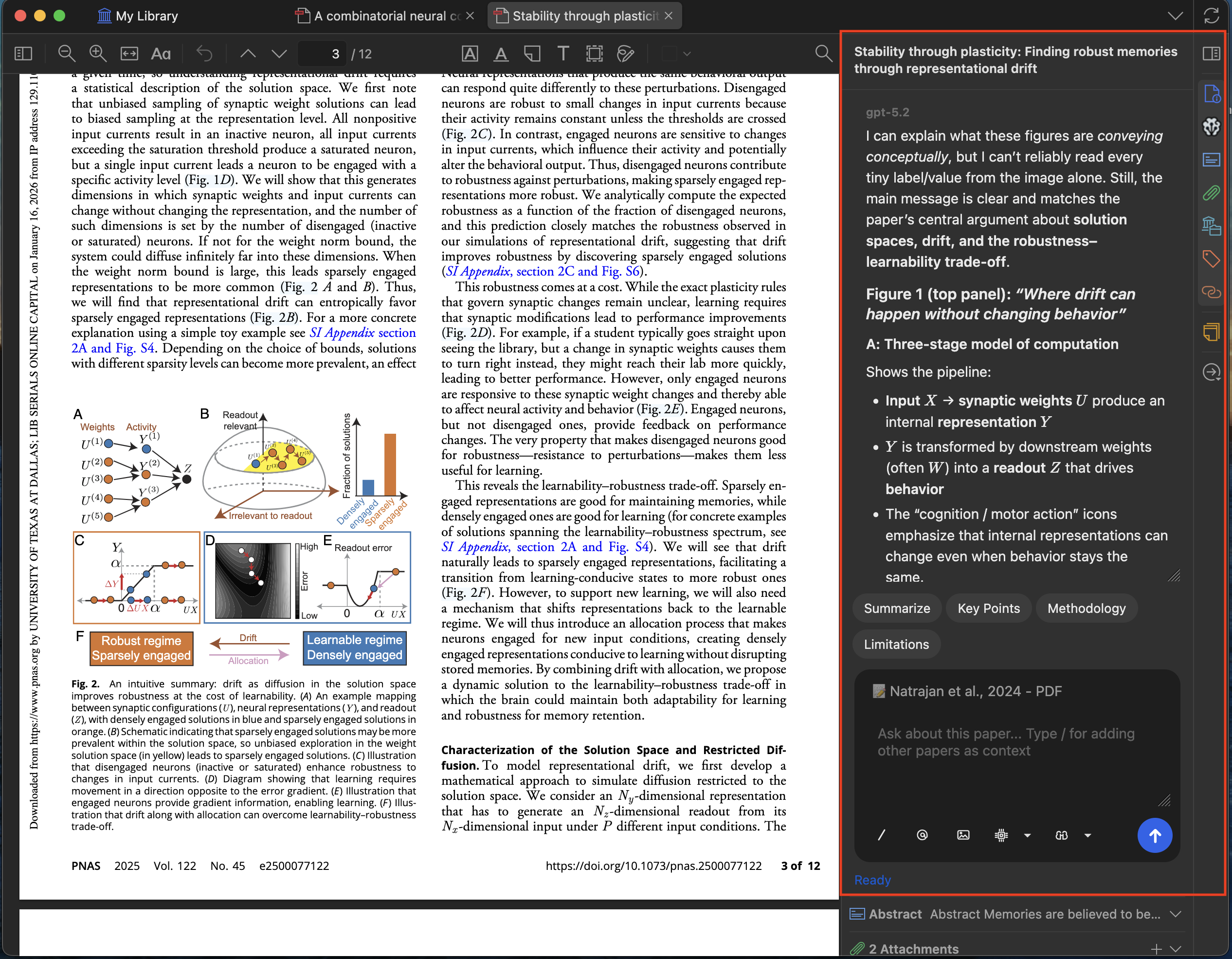
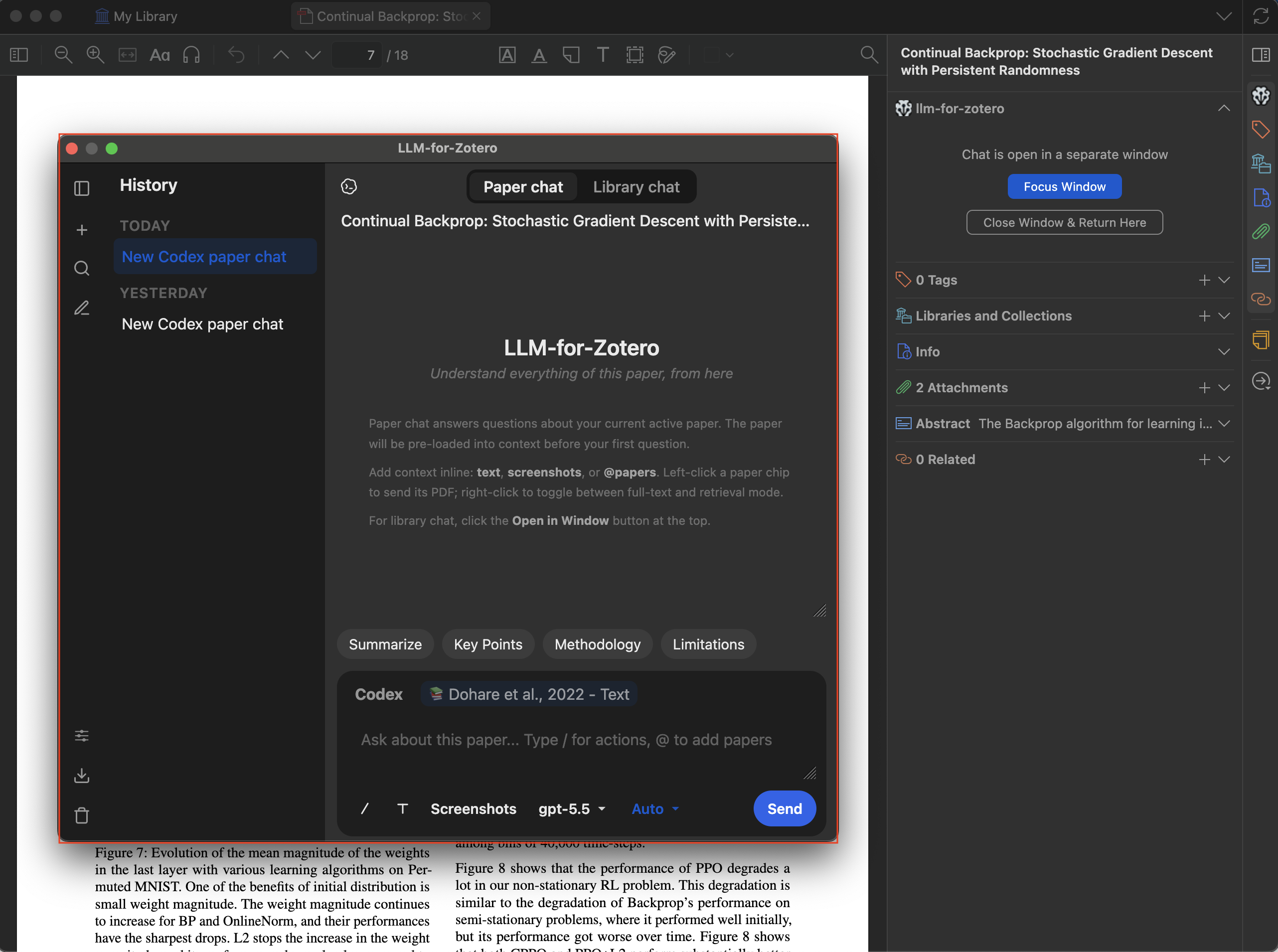
就任意打开的 PDF 提问,回答基于论文内容并附带可点击的引用跳转。
多模型支持OpenAI、Anthropic、Google Gemini、DeepSeek、Moonshot、本地 OpenAI 兼容模型等。
WebChat不想配置 API 密钥时,可通过 Sync for Zotero 浏览器扩展使用 ChatGPT 或 DeepSeek 网页端。
Agent 模式自主管理文库、执行终端命令、访问本地文件的智能代理——所有变更均需您审批。
MinerU PDF 解析可使用云端 MinerU 或本地 mineru-api 服务,进行高保真 PDF 解析,保留表格、公式、图表和复杂版式。
精准图像提取提问某张图时,Agent 会直接从原始 PDF 裁出该图——清晰、准确,并可直接嵌入笔记。
独立窗口模式在独立窗口中打开 LLM 助手,提供全尺寸聊天界面和对话历史侧栏。
文件笔记将研究笔记保存为 Markdown 文件,可写入 Obsidian、Logseq 或任意本地笔记目录,并保留元数据、引用和图表。
可自定义技能8 个内置技能引导 Agent 针对常见任务采用合适工作流,支持通过 Markdown 文件创建自定义技能。
Codex 与 Claude Code通过本地 app-server 使用 Codex,或通过本地桥接服务运行实验性的 Claude Code 对话。
快速开始
- 从 Releases 页面下载最新
.xpi文件。 - 在 Zotero 中打开
工具→附加组件→ 齿轮图标 → 从文件安装附加组件,选择该.xpi文件。 - 重启 Zotero。
- 打开
首选项→llm-for-zotero,选择服务商,填写基础 URL、密钥和模型,然后点击测试连接。 - 在 Zotero 中打开一篇 PDF,点击右侧工具栏的 LLM Assistant 图标。
如果您不想使用服务商 API 密钥,可以从 WebChat 或 Codex App Server 开始。
环境要求
- Zotero
- 一种模型后端:服务商 API 密钥、本地 OpenAI 兼容模型、WebChat、Codex App Server 或 Claude Code。
- WebChat 模式需要 Chromium 内核浏览器。
- 通过 npm 安装 Codex CLI 和运行 Claude Code 桥接服务需要 Node.js 18+。macOS Codex cask 不需要单独安装 Node.js。
- 如果启用 MinerU 解析,建议使用个人 MinerU API 密钥或本地
mineru-api服务。
选择配置方式
| 目标 | 推荐路径 | 是否需要 API 密钥 |
|---|---|---|
| 使用 OpenAI、Gemini、DeepSeek、Moonshot 或其他服务商 | 在 Zotero 首选项中配置 API 服务商 | 是 |
| 使用本地模型 | 连接任意 OpenAI 兼容的本地 HTTP API | 通常不需要 |
| 在浏览器中使用 ChatGPT 或 DeepSeek | 通过 Sync for Zotero 扩展使用 WebChat | 不需要 |
| ChatGPT Plus 用户使用 Codex 模型 | Codex App Server | 不需要单独 API 密钥 |
| 在 Zotero 内使用 Claude Code | Claude Code 桥接服务 | 需要 Claude Code 认证 |
| 提升表格、公式和图表的 PDF 提取质量 | MinerU PDF 解析 | 建议使用个人 MinerU 密钥 |
最新更新
- Codex App Server 是 ChatGPT Plus 用户推荐的 Codex 使用路径。它通过本地
codex app-server运行时工作,并在 Agent 标签页中配置。 - Claude Code 模式(实验性):通过配套本地桥接服务,将 Claude Code 作为 Zotero 内部独立的对话系统运行。该模式仍在开发中,目前尚不支持原生 Zotero API 操作;后续计划加入原生 Zotero 工具支持。详见 Claude Code 配置。
- WebChat 模式 通过 Sync for Zotero 浏览器扩展支持 ChatGPT 和 DeepSeek 网页同步。
- 文件笔记:笔记目录不再硬编码为 Obsidian。您可以配置任意本地 Markdown 目录,包括 Obsidian、Logseq 或普通文件夹。详见 文件笔记。
- Skills 技能系统:可自定义的引导文件会影响 Agent 的任务处理方式。内置 8 个技能,并支持创建自定义技能。详见 Skills 技能系统。
- 独立窗口模式:在专用窗口中打开助手,支持论文对话、文库对话和对话历史。
- 缓存感知的 Agent 模式:在较长研究回合中保留稳定的论文上下文、已读取证据和覆盖状态,并在上下文窗口拥挤时自动压缩旧对话历史。
- 引用跳转:在页码位置经过验证前保持保守的引用标签;基于原文片段的引用可跳回 Zotero 中匹配的段落。
- MinerU PDF 解析:高保真提取可更准确地保留表格、公式和图表,并支持云端 MinerU、本地
mineru-api服务、批量解析、缓存修复、同步包、标签和解析过滤器。 - 精准图像提取:图像问答与图像笔记现在使用直接从原始 PDF 裁出的图像(以 MinerU 为索引),而非 MinerU 自身的图片,从而获得更清晰、更准确的图像。详见精准图像提取。
感谢 @jianghao-zhang 和 @boltma 对 Codex App Server、Claude Code 和文件上传工作流的重要贡献。
安装
下载最新的
.xpi安装包 前往 Releases 页面 下载最新的.xpi文件。在 Zotero 中安装插件 打开 Zotero →
工具→附加组件→ 点击齿轮图标 → 从文件安装附加组件 → 选择.xpi文件。重启 Zotero 重启 Zotero 完成安装。插件会在每次启动时自动检查更新。
配置
打开 首选项 → 切换到 llm-for-zotero 标签页。
- 选择您的服务商(如 OpenAI、Gemini、DeepSeek)。
- 填写 API 基础 URL、API 密钥 和模型名称。
- 点击 测试连接 以验证配置。

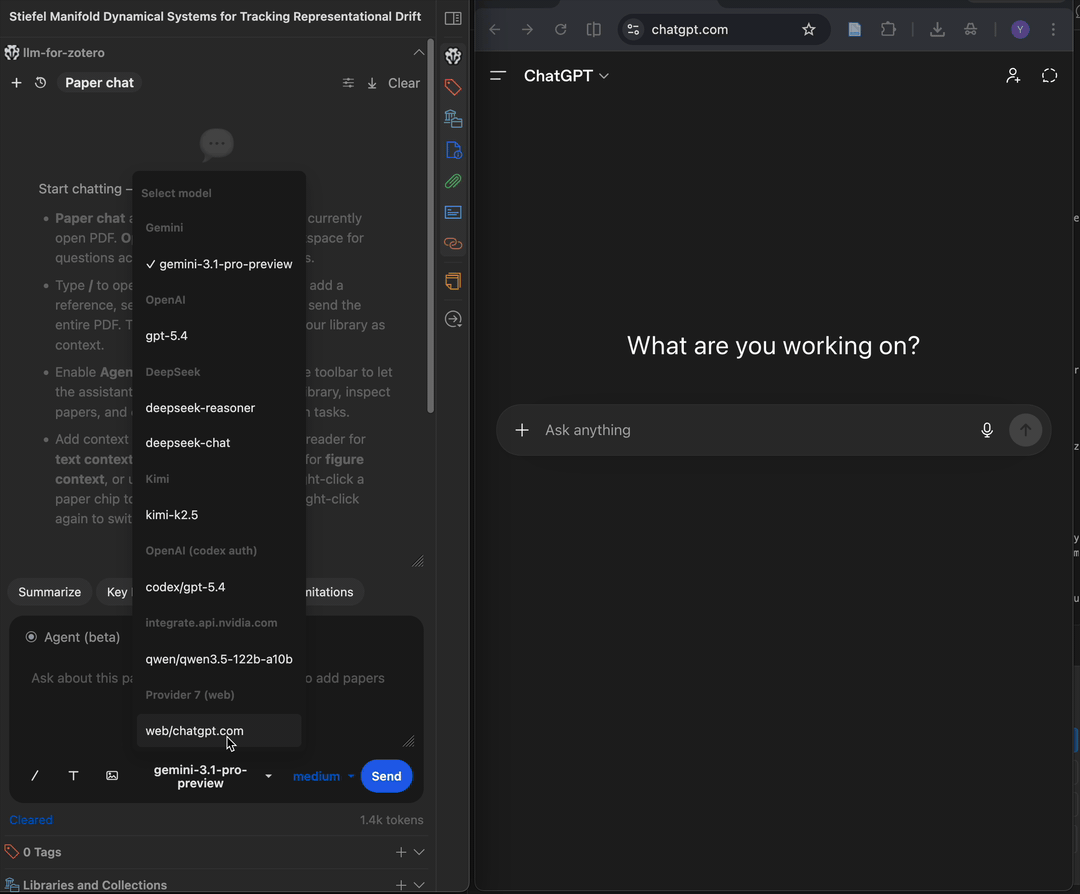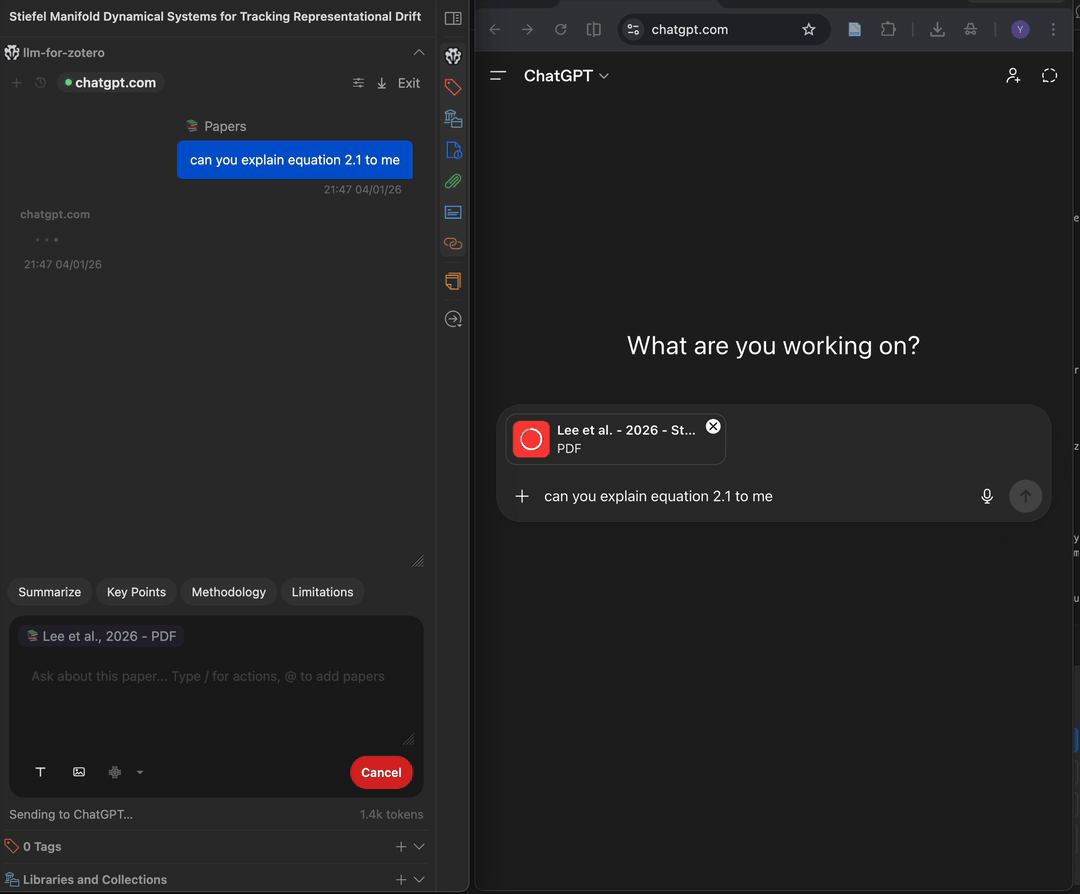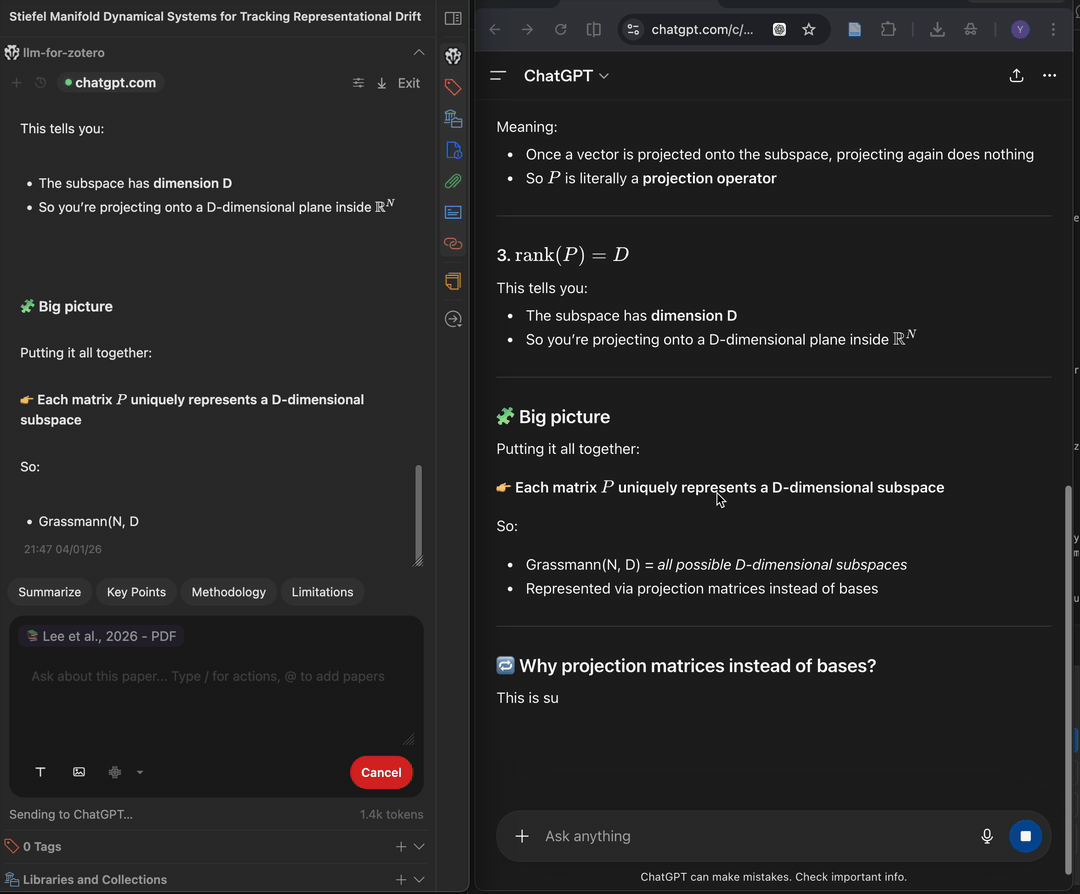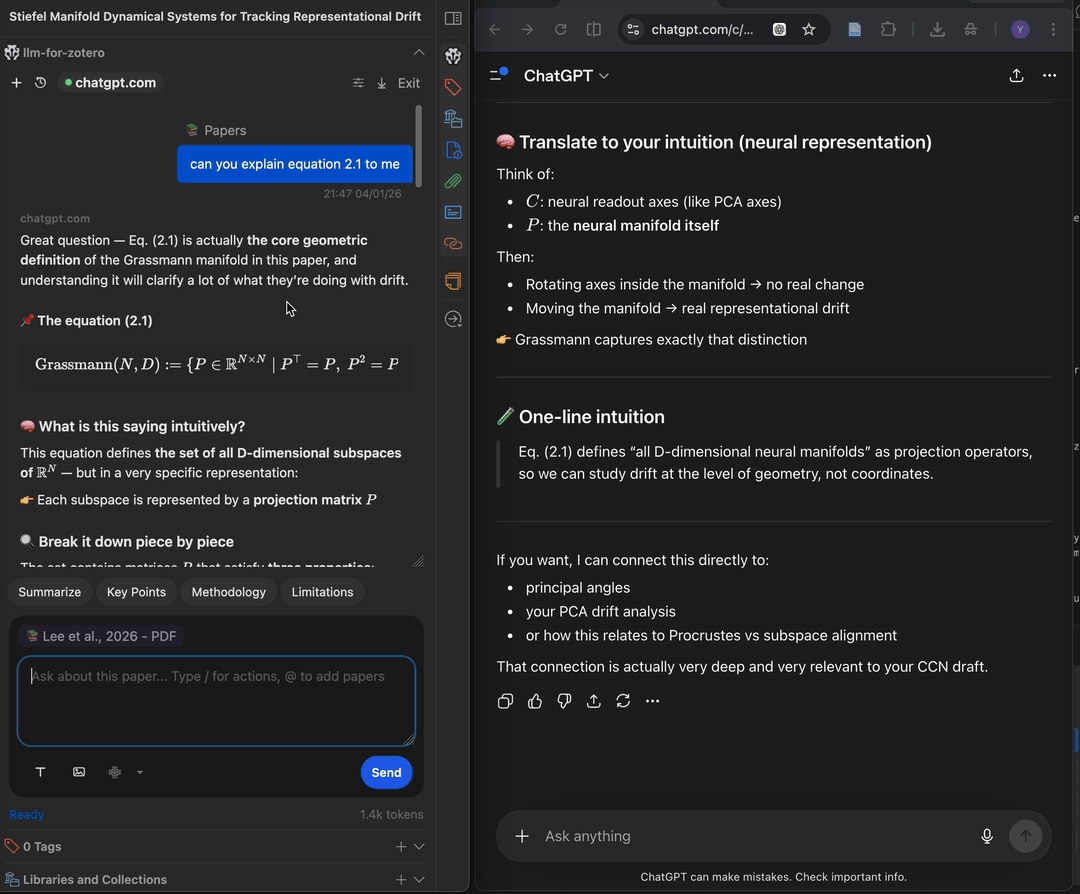
支持的服务商与协议
预设服务商包括 OpenAI、Gemini、Anthropic、MiniMax、GLM、DeepSeek、Grok、Qwen、Kimi 和 GitHub Copilot。您也可以添加任意自定义 OpenAI 兼容 HTTP 端点,包括 Ollama、LM Studio、vLLM 或远程代理。
插件原生支持以下服务商协议:
| 协议 | 说明 | 主要功能 |
|---|---|---|
responses_api | OpenAI Responses API | 流式输出、工具调用、文件上传、多模态 |
openai_chat_compat | OpenAI 兼容聊天 API | 流式输出、工具调用、多模态 |
anthropic_messages | Anthropic Messages API | 流式输出、工具调用、多模态 |
gemini_native | Google Gemini API | 流式输出、工具调用、多模态 |
codex_responses | Codex App Server / Codex Auth (Legacy) | ChatGPT Plus 订阅用户可免单独 API 密钥使用 Codex 模型,推荐选择 Codex App Server |
web_sync | ChatGPT / DeepSeek 的 WebChat 桥接协议 | 通过浏览器扩展转发,无需服务商 API 密钥 |
支持的模型
| API 地址 | 模型 | 推理等级 | 备注 |
|---|---|---|---|
https://api.openai.com/v1/responses | gpt-5.4 | default, low, medium, high, xhigh | 支持 PDF 上传 |
https://api.openai.com/v1/responses | gpt-5.4-pro | medium, high, xhigh | 支持 PDF 上传 |
https://api.deepseek.com/v1 | deepseek-chat | default | |
https://api.deepseek.com/anthropic | deepseek-v4-flash | default | |
https://generativelanguage.googleapis.com | gemini-3-pro-preview | low, high | |
https://generativelanguage.googleapis.com | gemini-2.5-flash | medium | |
https://generativelanguage.googleapis.com | gemini-2.5-pro | default, low, high | |
https://api.moonshot.ai/v1 | kimi-k2.5 | default |
任何提供 OpenAI 兼容 HTTP API 的模型均可使用,包括通过 Ollama、LM Studio 或 vLLM 本地部署的模型。
多服务商配置
您可以配置最多 10 个服务商组,每组包含多个模型,从而:
- 用多模态模型解读图表,用文本模型生成摘要。
- 通过多个模型交叉验证答案,获得更全面的理解。
- 在对话中随时通过模型选择器切换模型。
推理等级与超参数
对于支持的模型,您可以为每次请求设置推理等级:default、low、medium、high 或 xhigh,用于控制模型在回答前的思考深度。
其他可调参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| Temperature | 控制输出随机性(0 = 确定性,2 = 创意性) | 1.0 |
| 最大输出 Token 数 | 限制模型回复长度 | 2048 |
| 输入 Token 上限 | 限制发送给模型的上下文大小 | 模型默认值 |
| 系统提示词 | 每次请求前置的自定义指令 | — |
使用指南
- 在 Zotero 阅读器中打开任意 PDF。
- 点击右侧工具栏中的 LLM 助手图标以打开侧栏。
- 输入问题,例如“这篇论文的主要结论是什么?”
首条消息会将整篇论文作为上下文加载,后续问题则通过检索定位相关段落,保持对话快速且精准。
对话模式
插件支持三种对话模式:
| 模式 | 说明 |
|---|---|
| 论文对话 | 针对当前打开的 PDF 进行对话,上下文来自该论文。 |
| 全局对话 | 覆盖整个文库的对话,不限定于某篇论文。 |
| 笔记对话 | 编辑 Zotero 笔记时进行对话,以笔记内容为上下文。 |
界面控件
- 模型选择器 — 在对话中随时切换已配置的模型。
- 推理等级选择器 — 为当前请求选择推理深度。
- 字体缩放 — 将侧栏字体大小从 80% 调整至 180%。
- 自动滚动 — 自动滚动至最新消息。
- Token 用量 — 实时显示输入、输出及推理 Token 消耗。
带引用跳转的有据答案
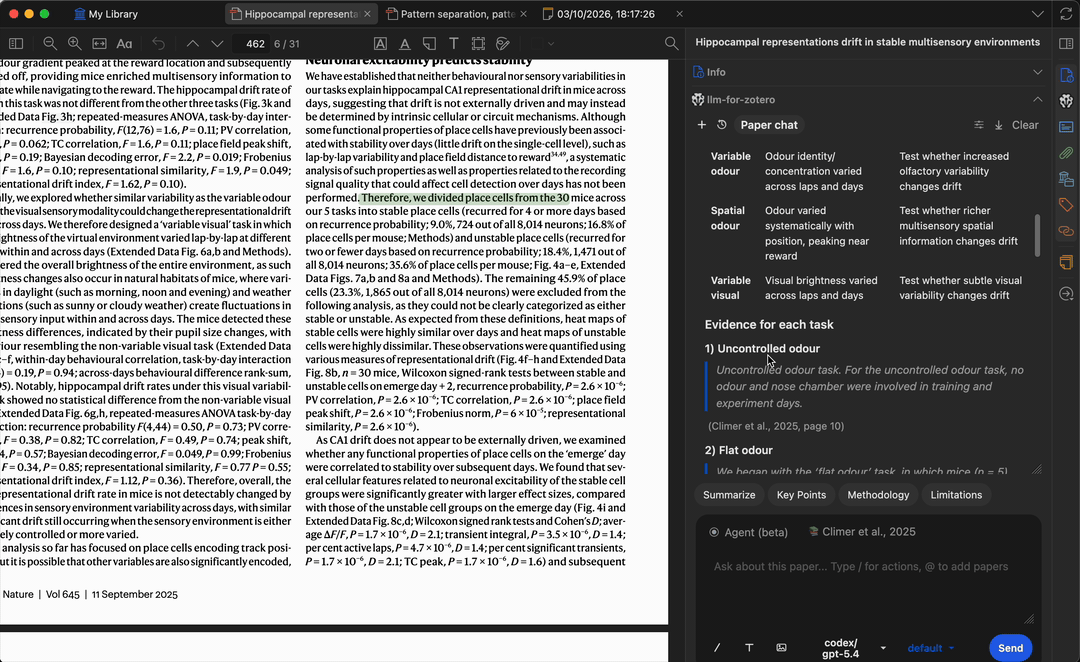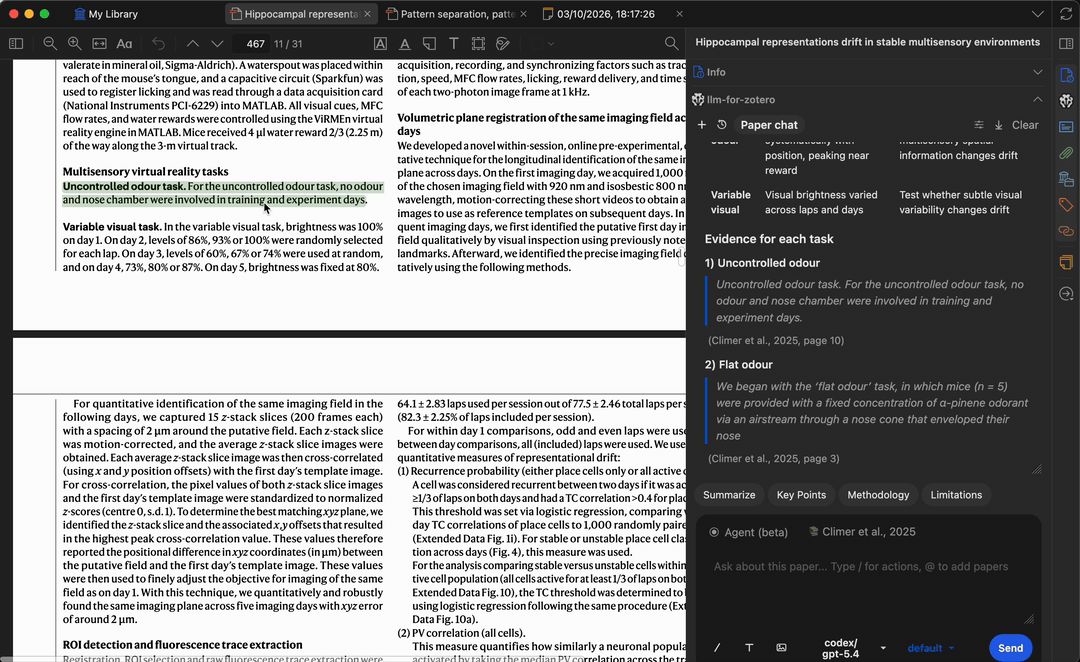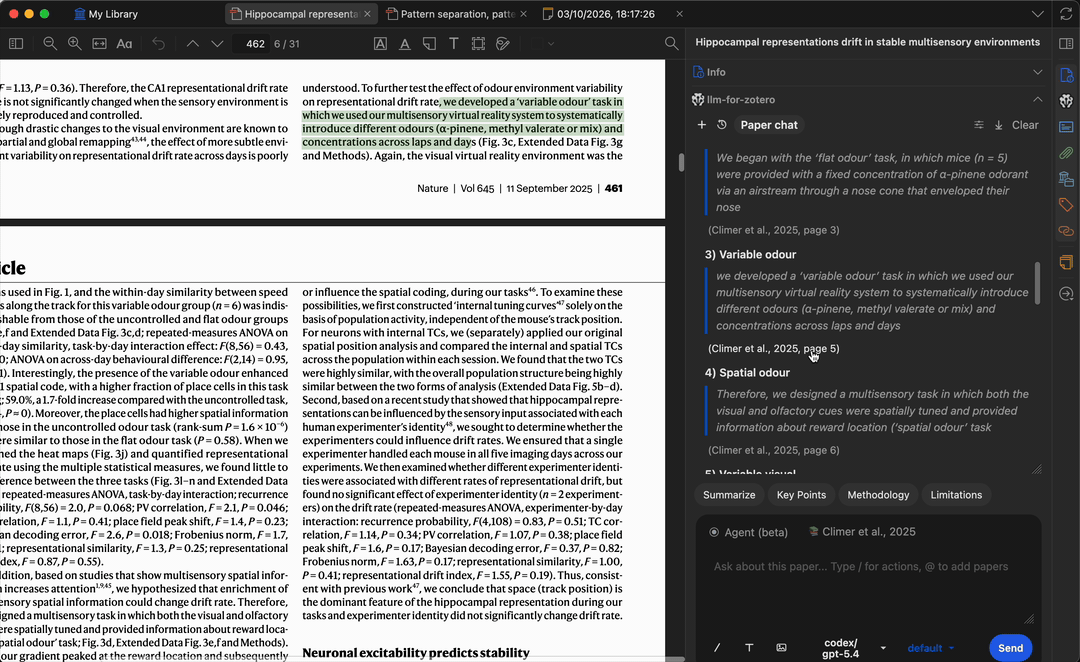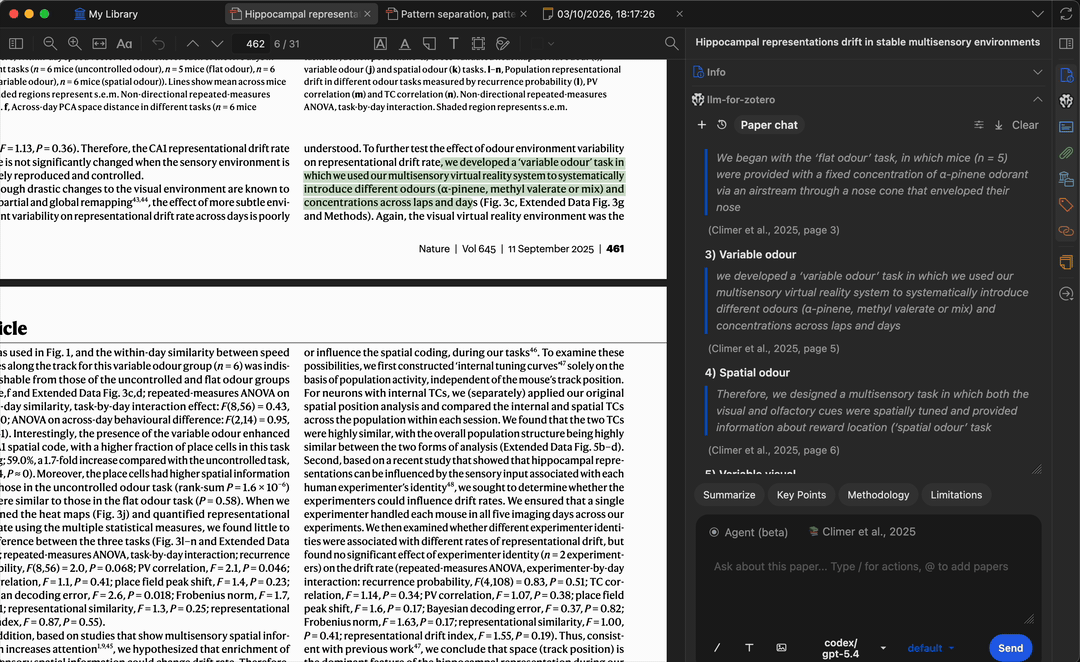
提问时,模型会生成基于论文内容的答案。引用标签会在页码位置经过验证前保持保守;点击已验证的引用或基于原文片段的引用,即可跳回 Zotero 中匹配的段落,方便核实答案并快速定位相关内容。
论文摘要生成
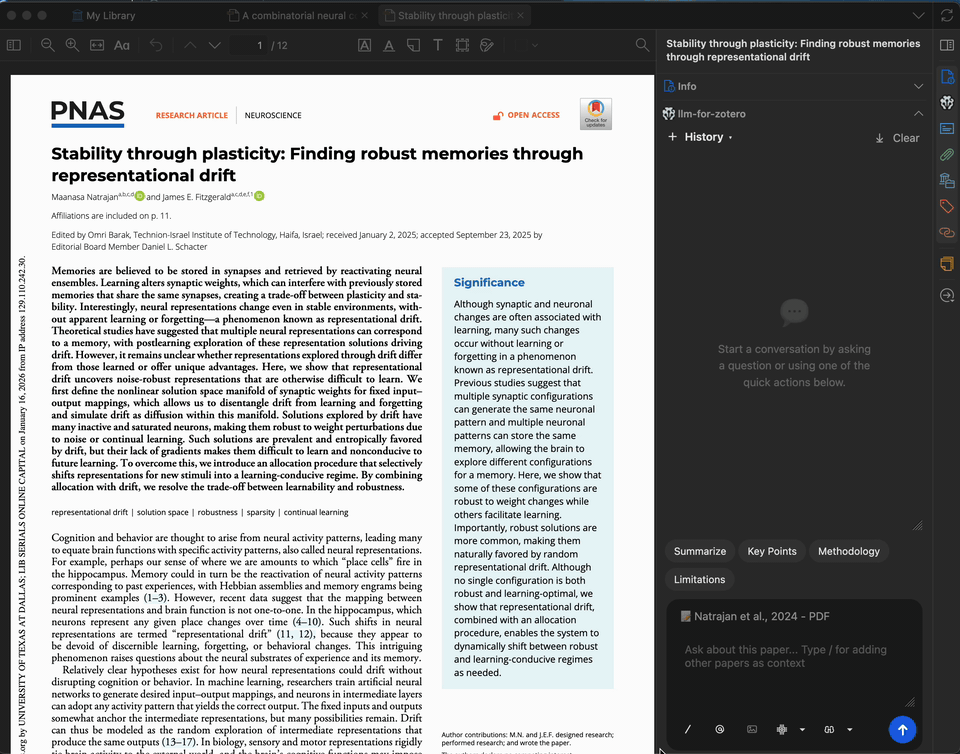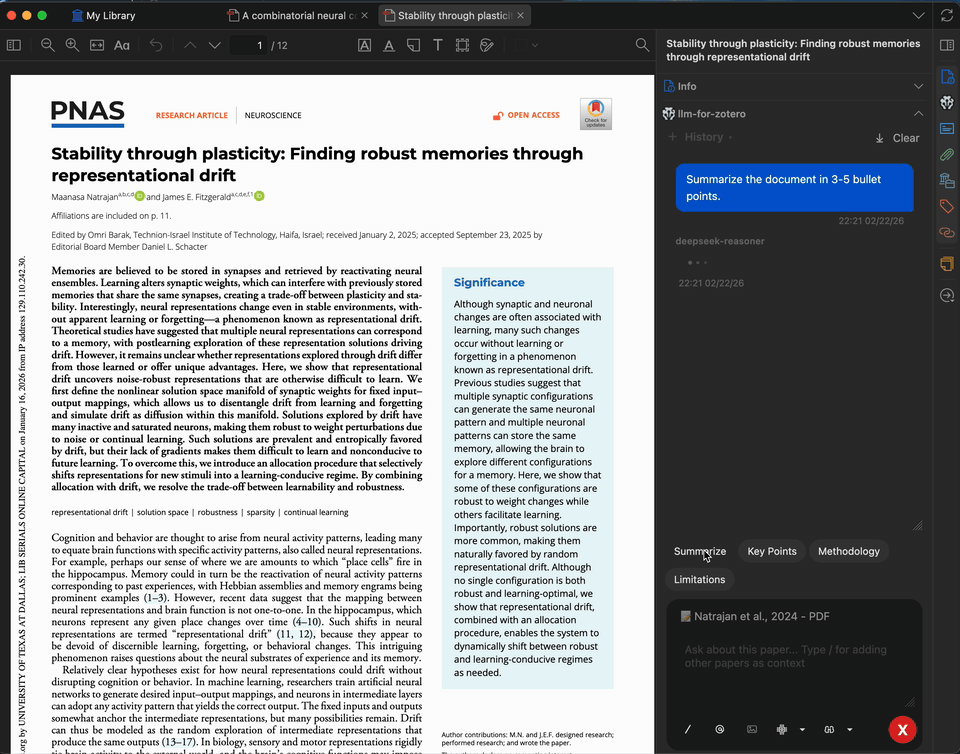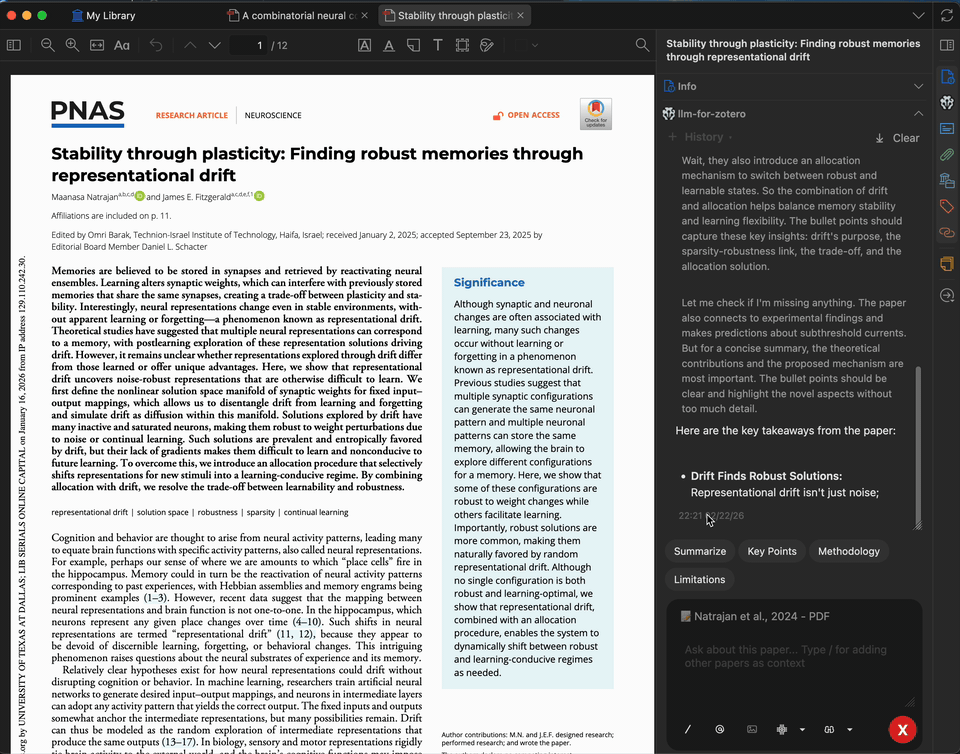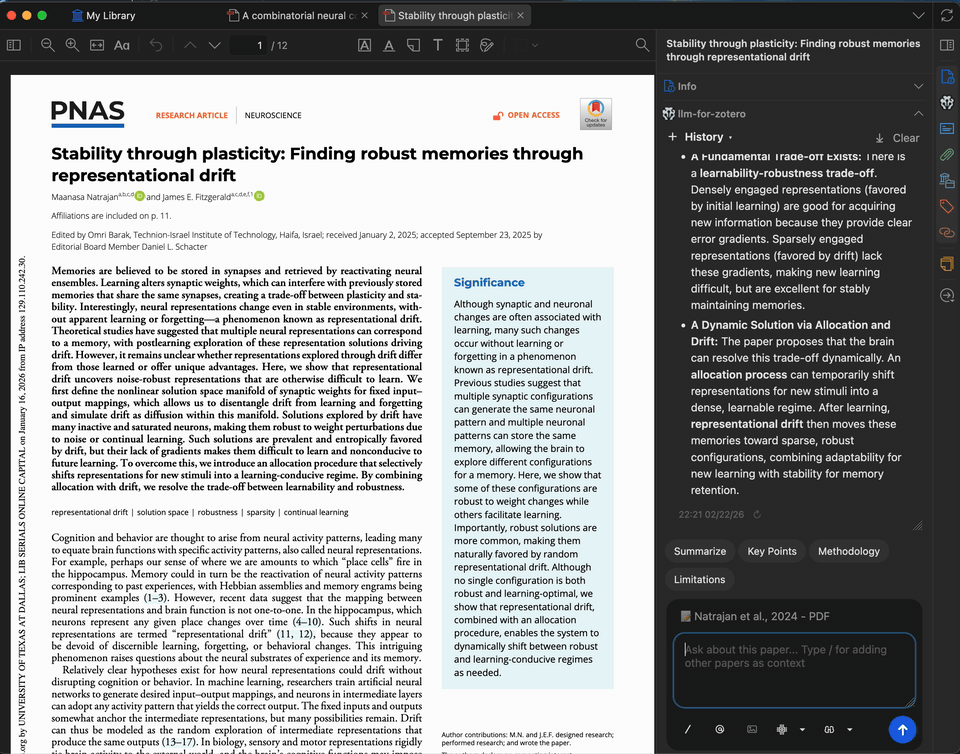
数秒内为任意论文生成简洁摘要。摘要基于完整 PDF 全文生成,您可以自定义提示词,聚焦于研究方法、结果、启示或其他任何方面。
选中文本解释
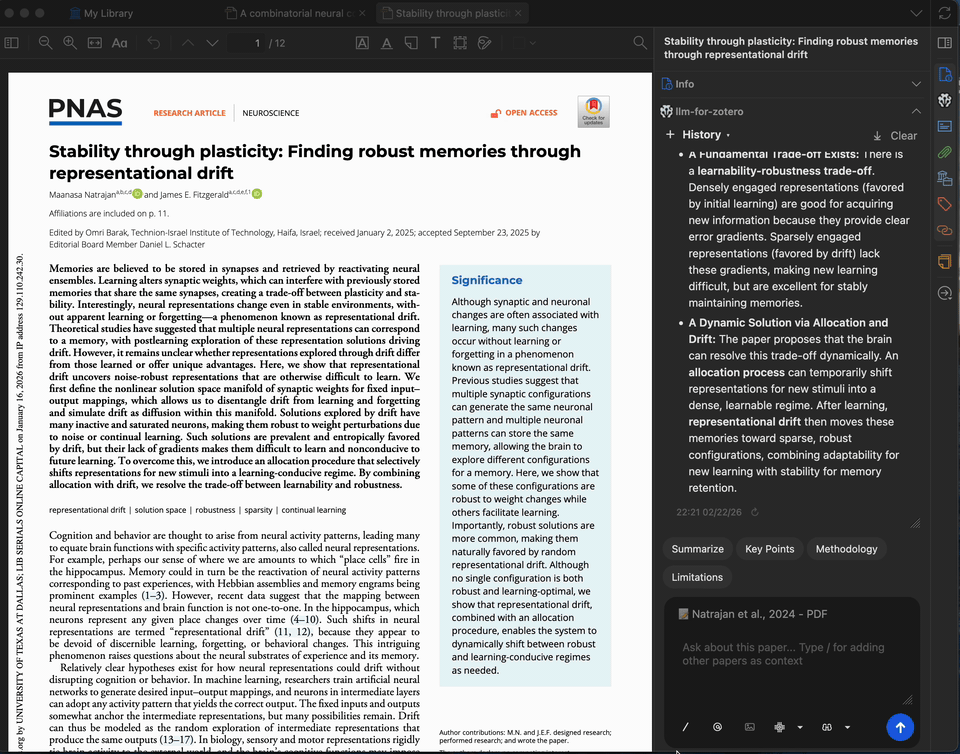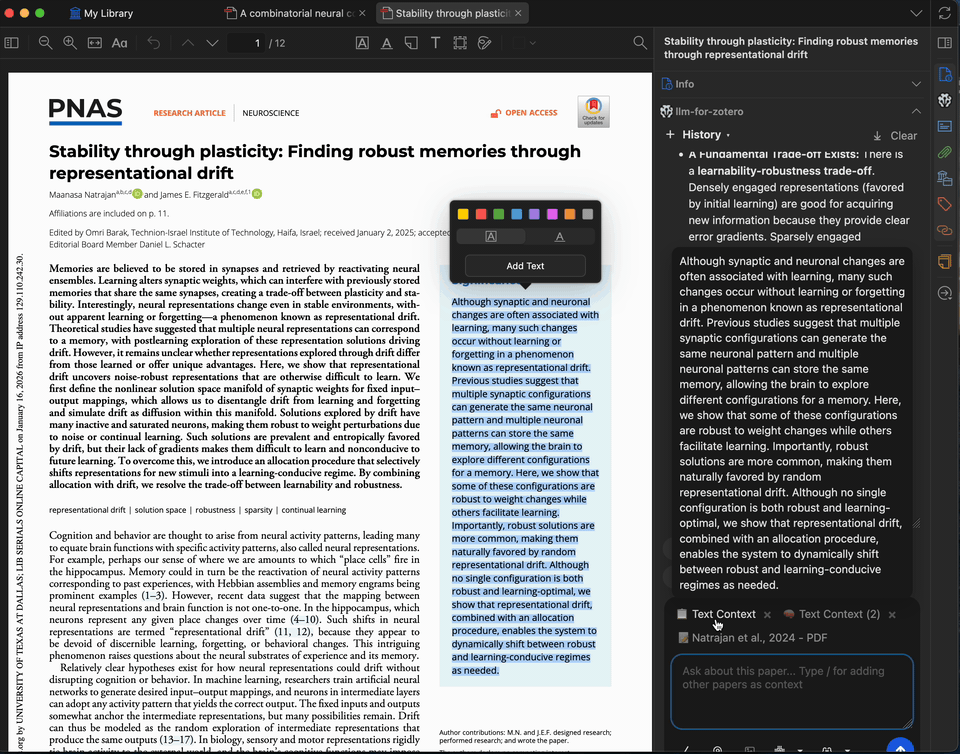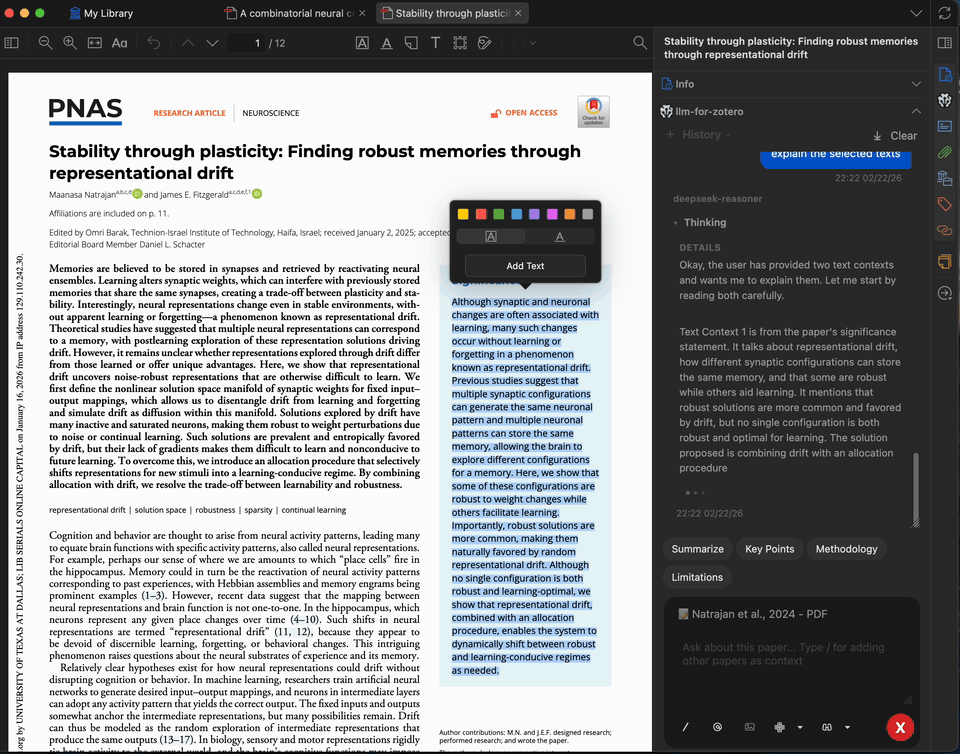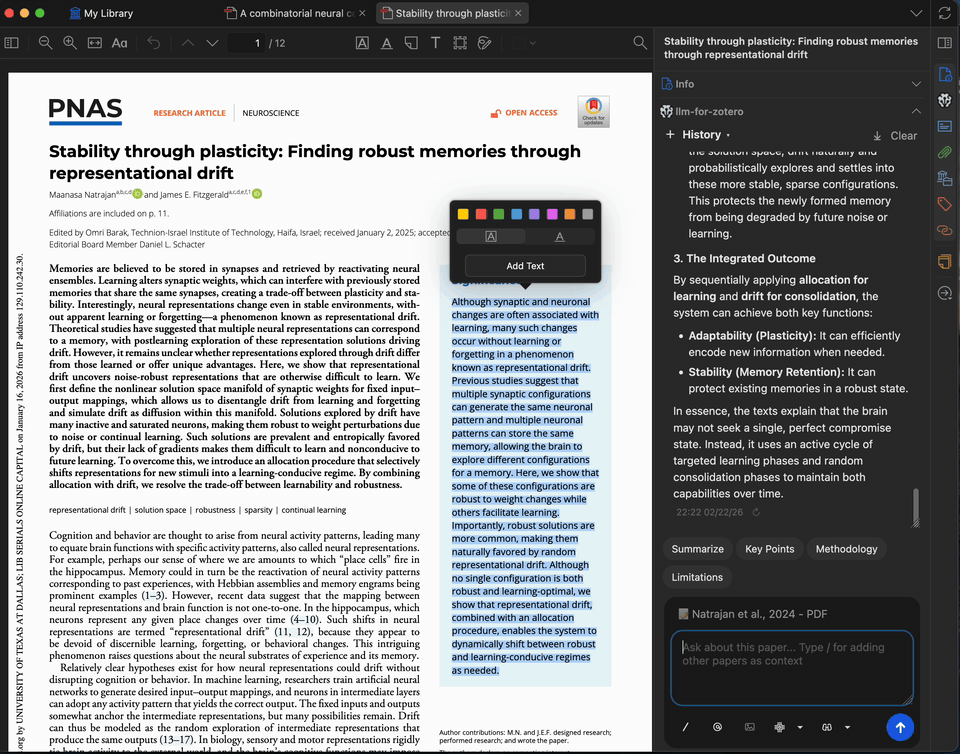
选中 PDF 中任意复杂段落或专业术语,请模型为其解释。您最多可添加 5 条上下文(来自论文或之前的回答)以进一步细化解释。
可选弹窗会自动建议将选中文本添加到对话,不喜欢可在设置中关闭。
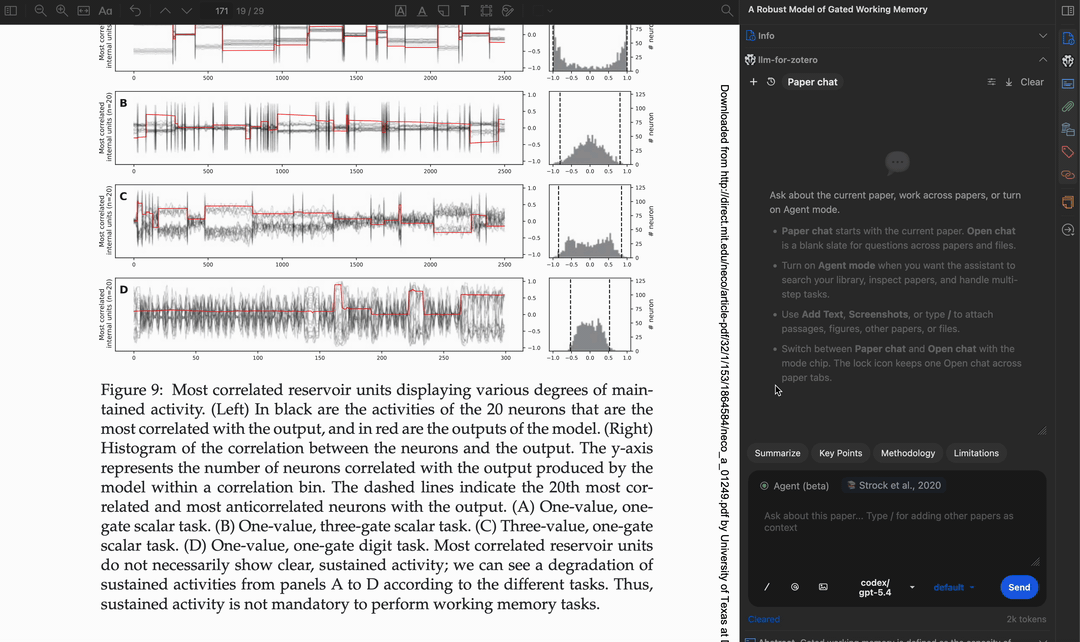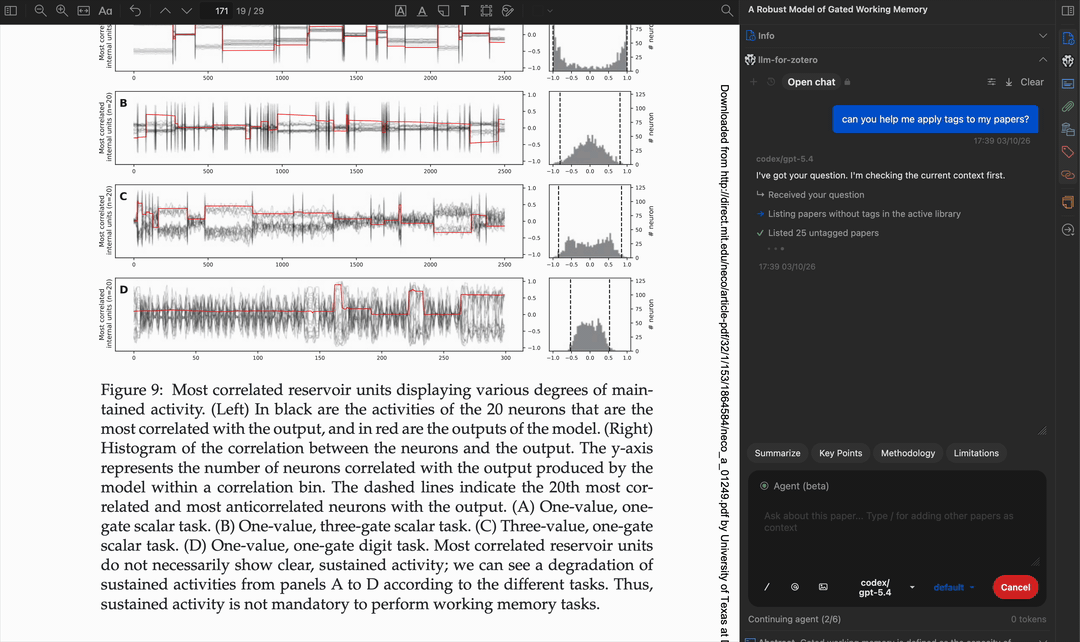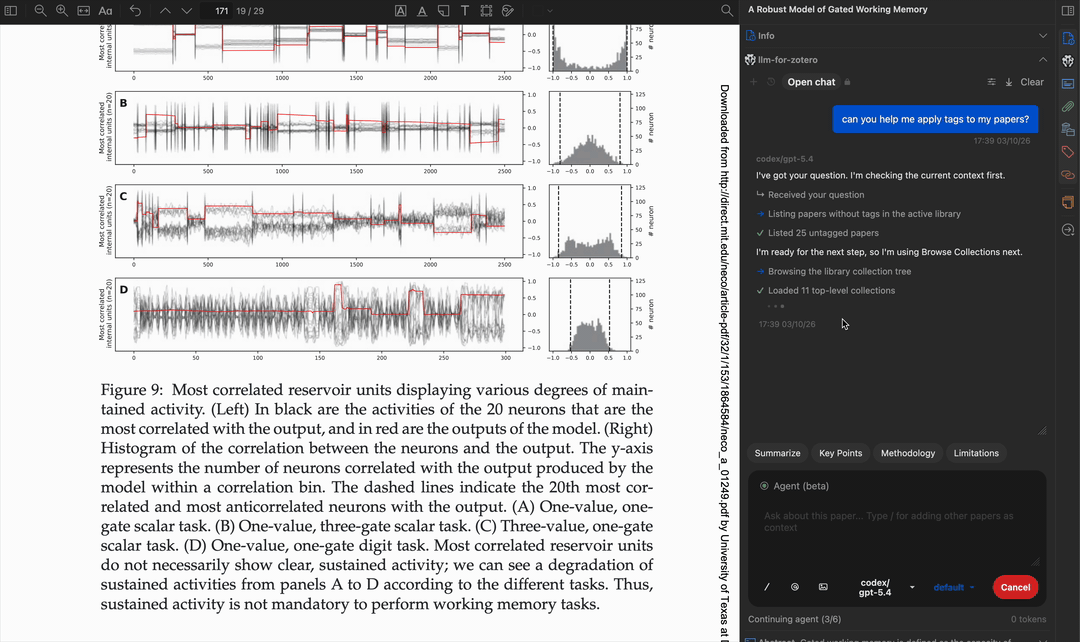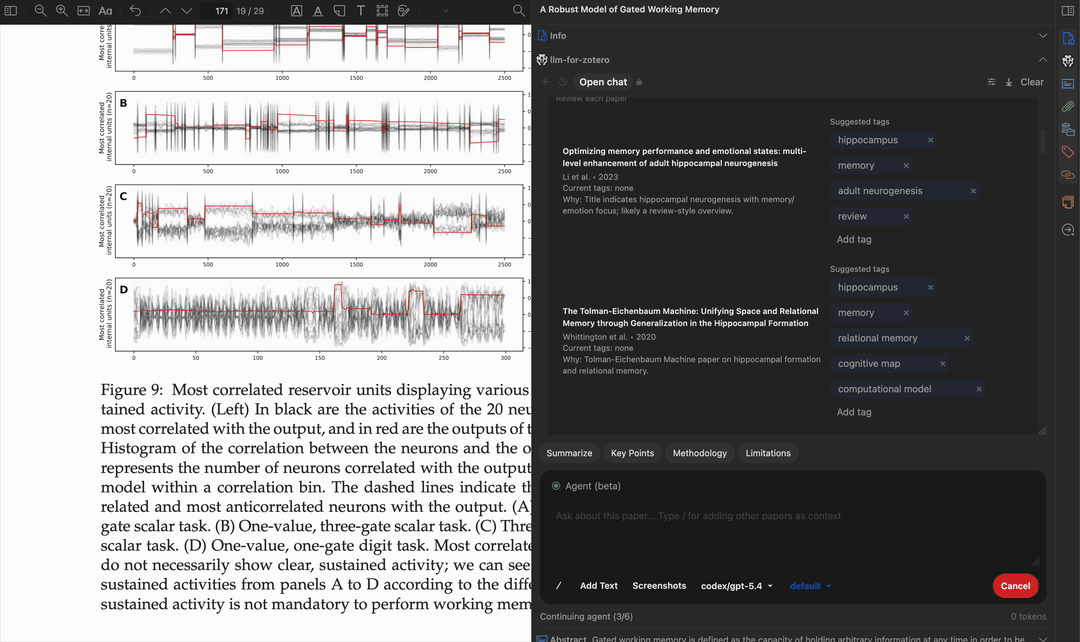
图表解读

截取任意图形、图表或示意图,请模型进行解读。每次最多支持 10 张截图,适合分析复杂的多面板图表或跨章节对比视觉内容。
跨论文对比

在不同标签页中打开多篇论文,并排对比。在输入框中输入 / 可引用其他已打开的论文作为额外上下文,单次对话最多可引用 10 篇论文,实现深度跨文献分析。
外部文档上传

从本地磁盘上传文档作为额外上下文,支持格式:
- PDF(每个文件最大 50 MB)
- DOCX(Word 文档)
- PPTX(PowerPoint 演示文稿)
- TXT(纯文本)
- Markdown(.md 文件)
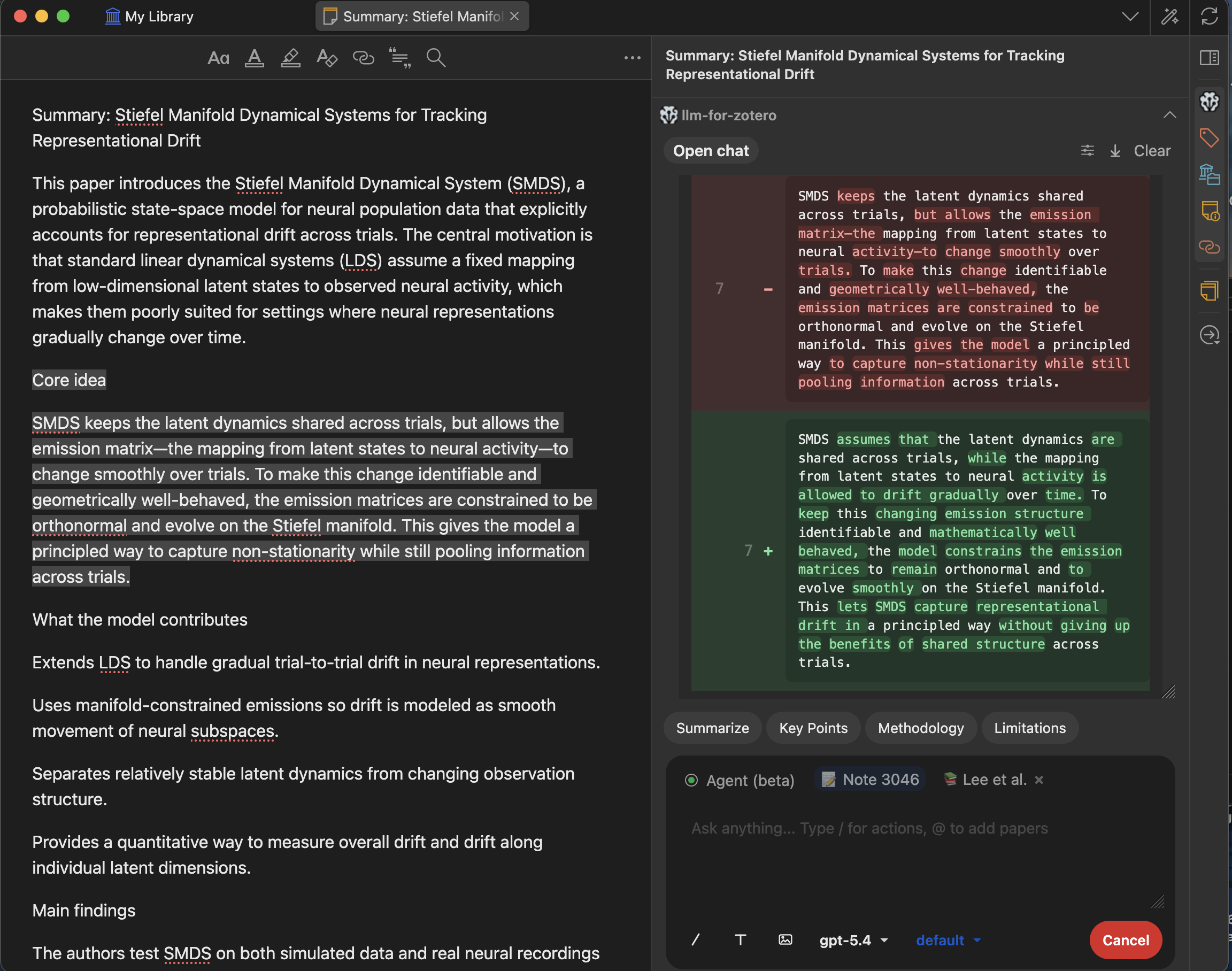
保存至笔记

一键将任意回答或选中文本直接保存到 Zotero 笔记,与您现有的笔记工作流无缝集成,无需手动复制粘贴。
对话历史与导出

对话会自动保存到本地并与对应论文关联。您可以:
- 在历史记录面板中浏览过往对话。
- 将完整对话以 Markdown 格式导出到 Zotero 笔记。
- 导出内容包含选中文本、截图,以及正确渲染的 LaTeX 数学公式。
自定义快捷预设
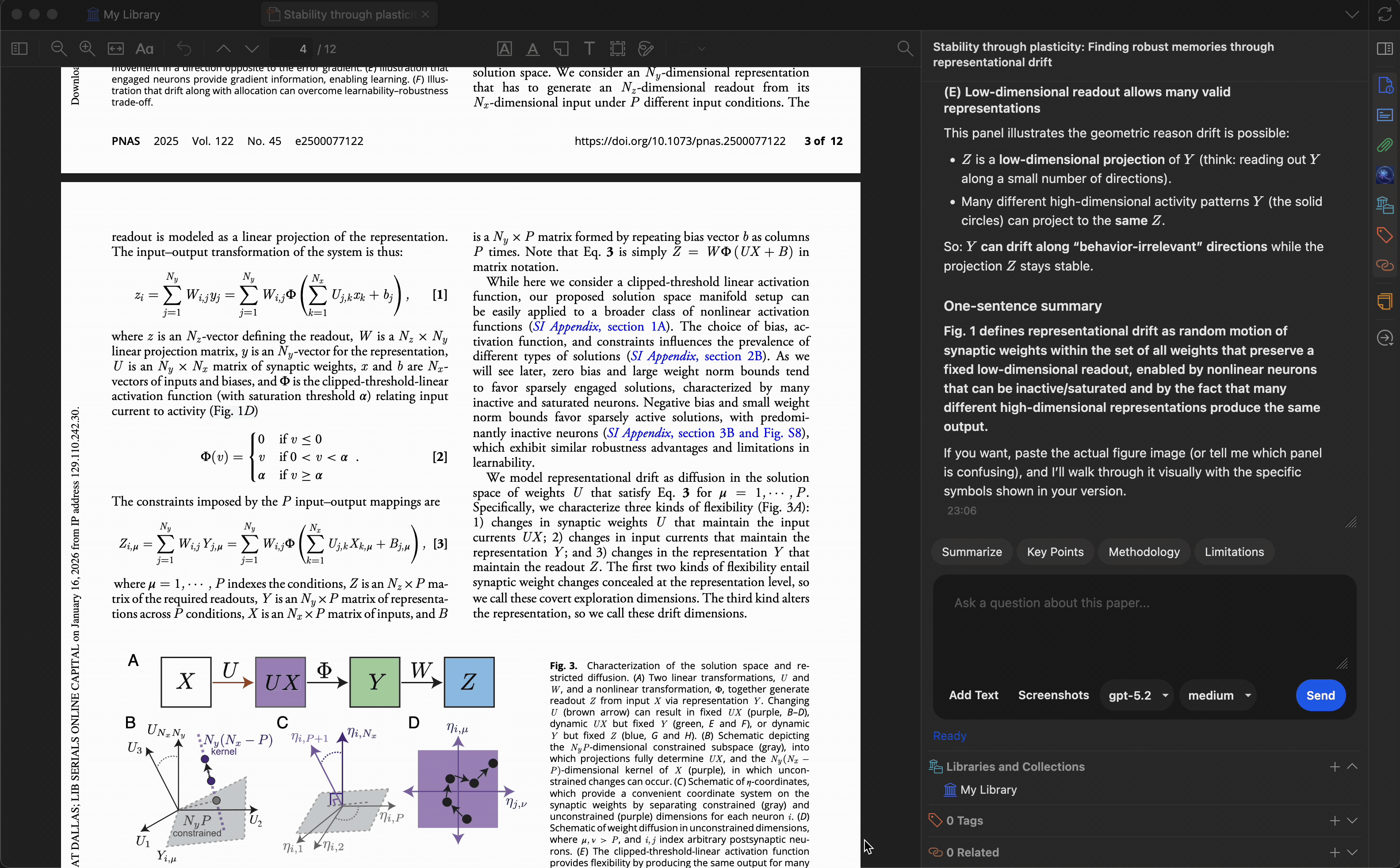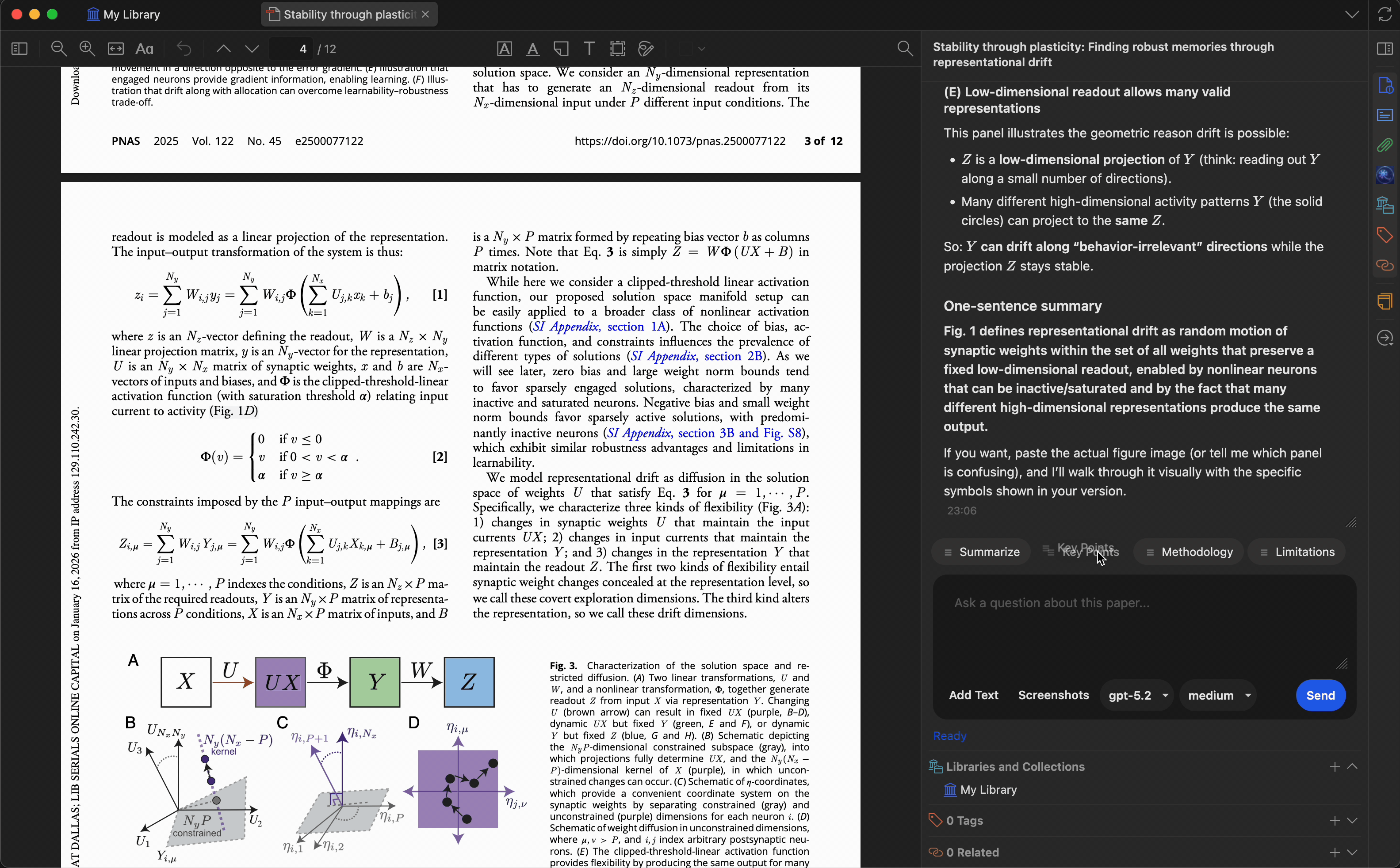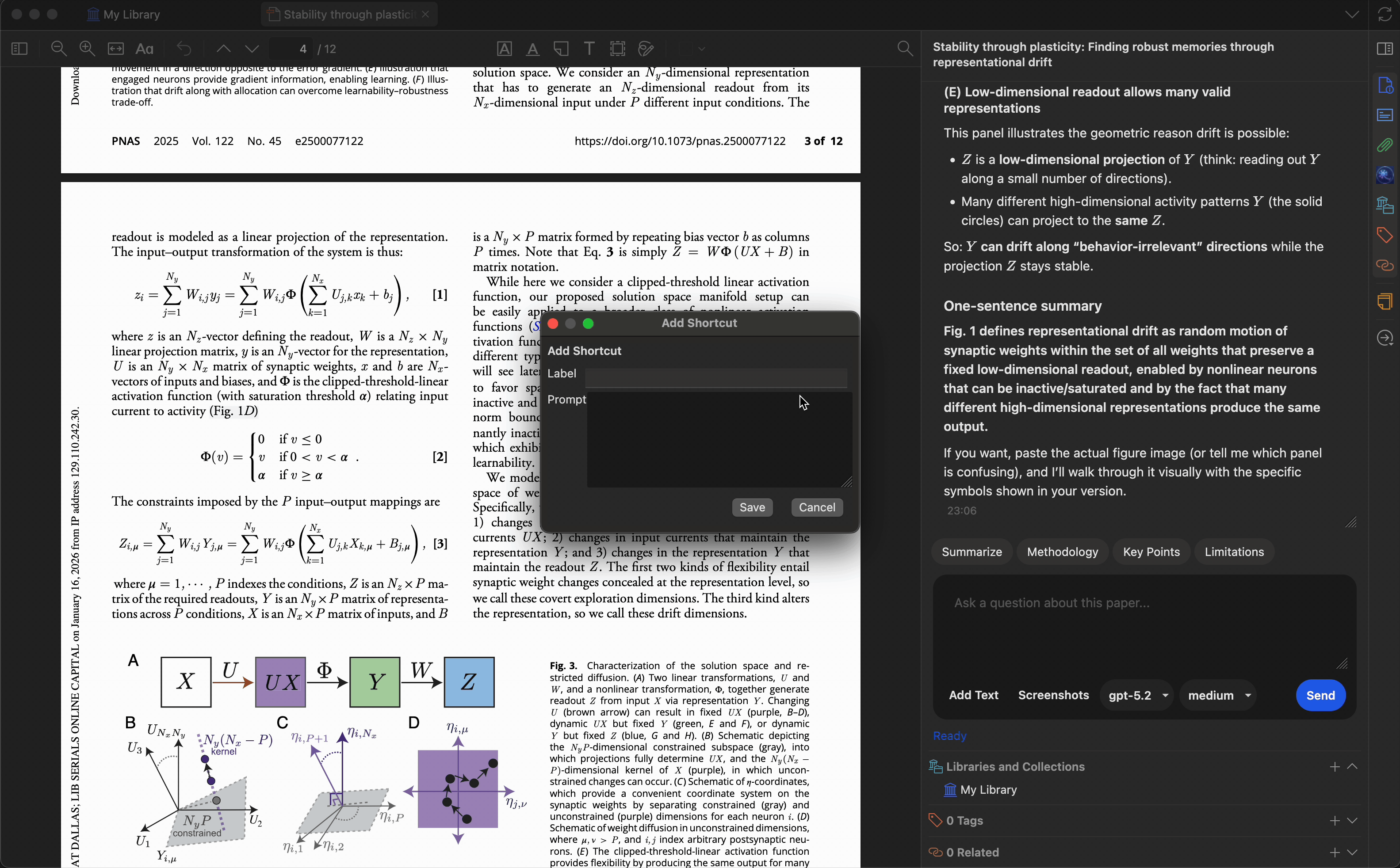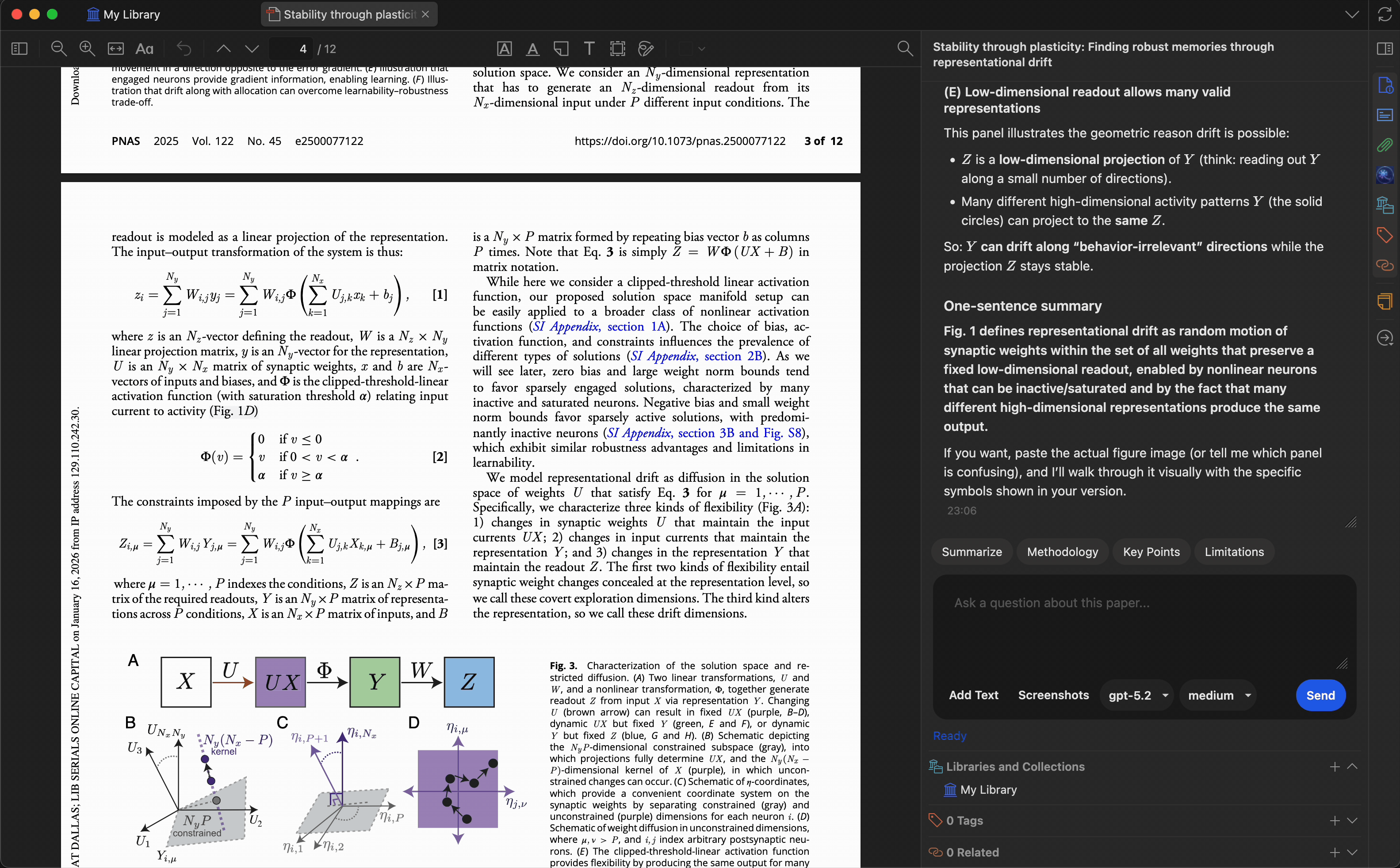
创建最多 10 个自定义预设,将常用提示词一键触发。内置预设包括:
- 总结 — 生成简洁摘要
- 关键要点 — 提取主要发现
- 研究方法 — 描述研究方法
- 局限性 — 识别不足或局限
您可以修改这些预设或添加自定义内容,以适配您的研究工作流。
独立窗口模式
在独立窗口中打开 LLM 助手,脱离 Zotero 阅读器侧栏。独立窗口提供全尺寸聊天界面,左侧配有可折叠的对话历史面板。
打开方式
| 方式 | 操作 |
|---|---|
| 快捷键 | Ctrl+Shift+L(macOS:Cmd+Shift+L) |
功能特点
- 论文对话与文库对话 — 通过顶部标签页切换论文级对话和文库级对话。
- 对话历史 — 在可折叠的左侧面板中按日期分组(今天、昨天、最近 7/30 天、更早)浏览历史对话。
- 功能完全一致 — 阅读器侧栏中的所有功能(截图、文件上传、Agent 模式、快捷预设、引用选择器)在独立窗口中均可正常使用。
- 搜索 — 通过搜索浮层快速查找历史对话。
独立窗口打开时,阅读器侧栏面板会显示占位提示,提供聚焦窗口(将独立窗口置于前台)和关闭窗口并返回侧栏两个选项。
文件笔记
除了 Zotero 内置笔记外,Agent 还可以将研究笔记保存为您指定本地目录中的 Markdown 文件。插件不绑定任何特定笔记软件:可以指向 Obsidian 知识库、Logseq 图谱,或普通 .md 文件夹。
配置
打开 首选项 → llm-for-zotero,滚动到 Notes Directory 部分。
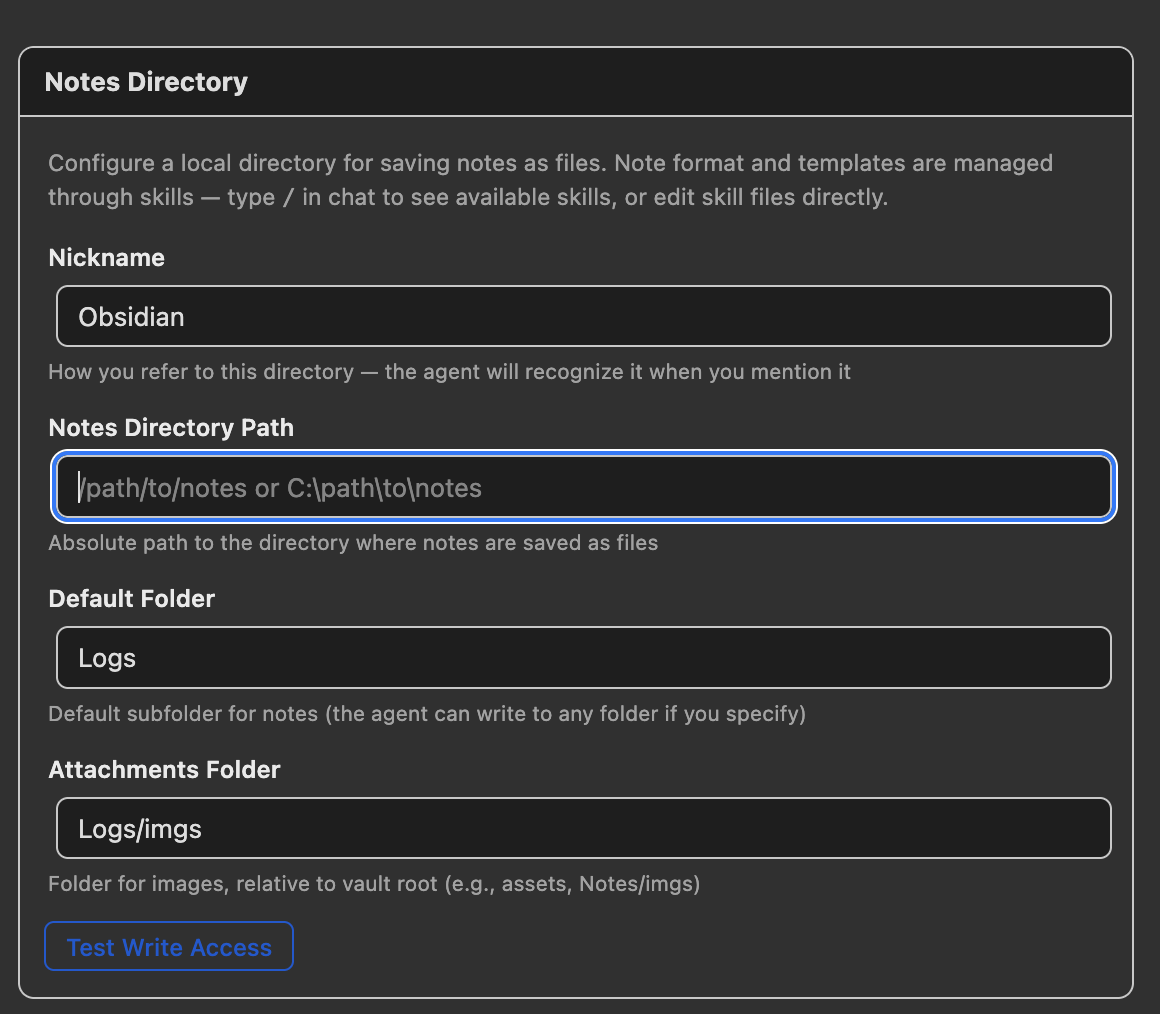
| 设置项 | 说明 | 示例 |
|---|---|---|
| Nickname | 在聊天中称呼该目录的名称;当您提到这个名称时,Agent 会识别它 | Obsidian、Logseq |
| Notes Directory Path | 保存笔记的根目录绝对路径 | /Users/me/MyVault |
| Default Folder | 新笔记默认写入的子文件夹;如果您明确要求,Agent 也可以写入其他文件夹 | Logs |
| Attachments Folder | 复制图表和图片的目录,相对于笔记目录根路径 | Logs/imgs |
点击 Test Write Access 验证插件是否有权限写入该目录。
工作原理
使用您配置的昵称要求 Agent 写笔记,例如“总结这篇论文并保存到 Obsidian” 或 “把这篇记录到我的 Logseq”。Agent 将:
- 采集内容:从论文中提取元数据、摘要、关键要点,并在可用时加入图表。
- 编写 Markdown 笔记:遵循
write-note技能中的约定。 - 添加 YAML 前置信息:匹配
write-note模板中的title、created、tags、citekey、doi、journal;作者信息保留在正文中。 - 嵌入提取的图像裁剪(按需):嵌入直接从原始 PDF 裁出的精准图像,并将其复制到附件文件夹。详见精准图像提取。
- 写入笔记:保存到
{notes_directory}/{default_folder}/{title}.md。
如果您希望笔记保存在 Zotero 内部,Agent 也可以通过 write-note 技能写入 Zotero 条目笔记。只需要求它“为这篇论文保存一条笔记”,不要提到外部笔记目录即可。
Zotero 笔记与文件笔记
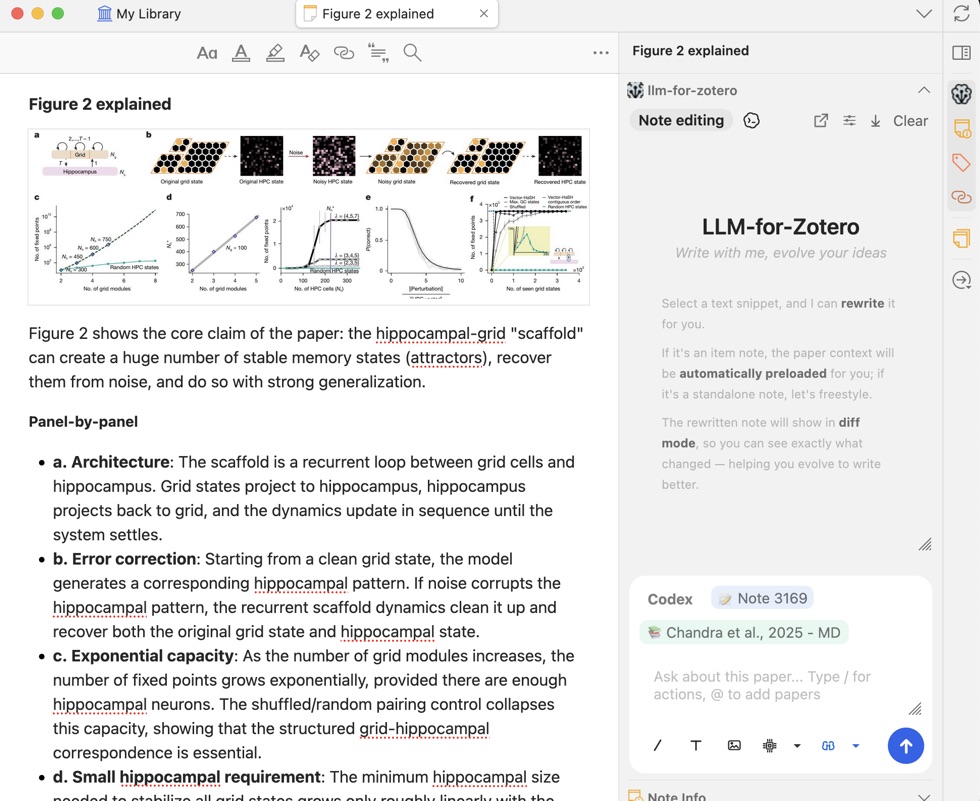
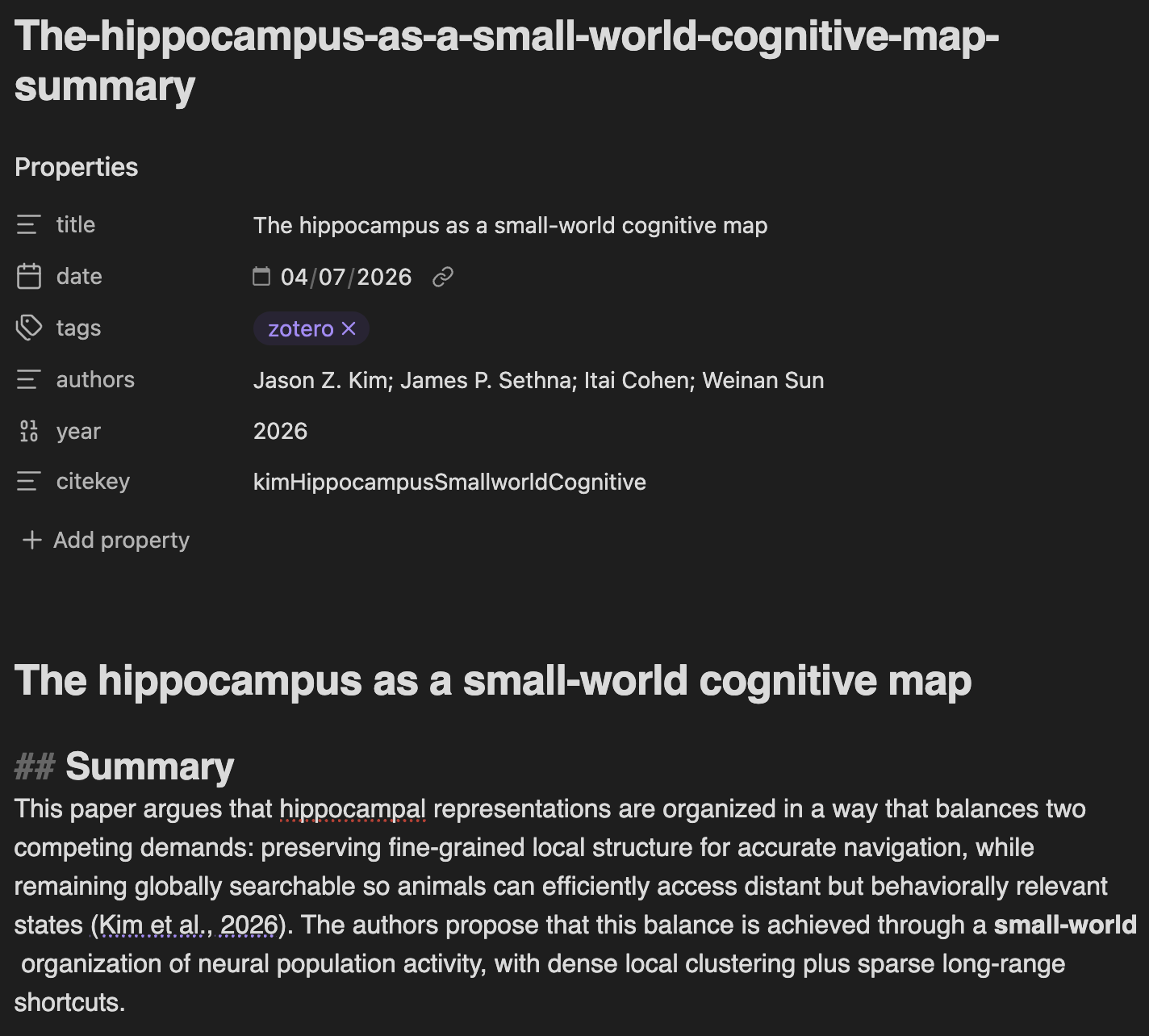
笔记使用 Pandoc 引用语法([@citekey]),兼容 Obsidian 的 Zotero Integration 和 Pandoc 插件,也适用于大多数 Markdown 阅读器。
write-note 技能中。打开独立窗口中的 Skills 面板即可自定义。Agent 模式(Beta)
启用后,LLM 将成为一个自主 Agent,可在 Zotero 文库中执行读取、搜索和写入操作。读取工具可直接运行;写入工具会进入确认卡片,并支持撤销。
较长的 Agent 运行具有缓存感知能力。插件会将稳定的 Zotero 上下文和已读取证据,与不断变化的聊天记录分开保存,跟踪哪些论文和段落已经被检查,并在模型上下文填满时自动压缩旧回合。后续问题可以在证据仍然相关时复用这些来源;当缺少所需来源或覆盖层级时,Agent 会重新读取。
文库与 PDF 读取工具
这些工具让 Agent 浏览您的文库、PDF、附件和在线学术资源,不会修改任何内容。
| 工具 | 说明 |
|---|---|
query_library | 发现 Zotero 条目和文集:搜索或列举任意条目类型,可按作者、年份、文集、条目类型或标签筛选,浏览文集树,查找相关论文和重复项 |
read_library | 读取一个或多个条目的结构化状态:元数据、笔记、注释、附件和文集归属 |
read_paper | 读取 PDF 文本内容,默认读取开篇章节,也可指定章节索引;单次最多 20 篇论文 |
search_paper | 通过问题在论文中查找证据,返回排序后的相关段落;单次最多 10 篇论文 |
view_pdf_pages | 将 PDF 页面渲染为图像,支持按问题、页码或当前阅读器视图捕获,用于视觉分析 |
read_attachment | 按 Zotero 附件 ID 读取 HTML 快照、文本文件、图片等附件,或将整个文件发送给模型 |
search_literature_online | 从 CrossRef、Semantic Scholar 等在线学术源搜索元数据、推荐、参考文献和引用 |
文库写入工具
所有写入工具均需人工确认后方可生效。
| 工具 | 说明 |
|---|---|
apply_tags | 为一篇或多篇论文添加或移除标签 |
update_metadata | 更新标题、作者、DOI、期刊、摘要等元数据字段 |
move_to_collection | 将论文加入或移出文集 |
manage_collections | 创建或删除文集 |
manage_attachments | 删除、重命名或重新链接损坏的附件文件路径 |
merge_items | 合并重复条目:保留主条目,将子项从其他条目移入,并将重复项移至回收站 |
trash_items | 将条目移至回收站 |
import_identifiers | 通过 DOI、ISBN、arXiv ID 或 URL 导入论文 |
import_local_files | 从本地导入文件到 Zotero;Zotero 会为可识别 PDF 自动抓取元数据 |
edit_current_note | 编辑当前 Zotero 笔记,或用纯文本、Markdown、HTML 创建新笔记 |
undo_last_action | 撤销本次对话中最近一次已确认的写入操作 |
文件系统与脚本工具
Agent 包含面向本地文件、脚本和 Zotero 运行时自动化的系统级工具。
| 工具 | 说明 |
|---|---|
file_io | 读写本地文件系统中的文本和图片文件,支持 offset/length 局部读取 |
run_command | 在本地机器上执行 Shell 命令(macOS 使用 zsh,Linux 使用 bash,Windows 使用 cmd.exe),适合分析脚本和命令行工具 |
zotero_script | 在 Zotero 运行时内部执行 JavaScript;读取模式用于批量取数,写入模式用于自定义变更 |
典型使用场景:
- 运行 Python 或 R 脚本分析从文库中提取的数据。
- 将元数据导出为 CSV/JSON 供外部处理。
- 调用命令行工具(如
pandoc、ffmpeg、pdftotext)作为 Agent 工作流的一部分。 - 动态编写并执行脚本,转换或可视化您的研究数据。
- 读取本地数据文件,并将结果写回 Zotero 笔记。
内置动作
Agent 为常见文库管理工作流提供高级动作,自动串联多个工具。
| 动作 | 功能说明 |
|---|---|
| 文库审计 | 扫描整个文库或某个文集中元数据不完整、缺少 PDF、缺少标签等问题,并可将报告保存为 Zotero 笔记 |
| 自动标签 | 为当前论文、已选择论文、已选择文集或整个文库推荐标签,并打开可编辑的批量标签审阅对话框 |
| 补全元数据 | 审计目标论文缺失的书目信息,从外部源获取规范元数据,并通过一个审阅卡片确认更新 |
| 发现相关文献 | 通过推荐、参考文献或被引关系查找相关论文 |
| 整理未归档条目 | 查找未归档条目,通过交互式审阅流程归入文集 |
| 文献综述 | 启动引导式文献综述工作流 |
| 文库统计 | 汇总文库或文集的条目类型、年份、作者、期刊、文集、标签、注释和增长趋势等统计信息 |
MCP 服务器
插件运行内置的 Model Context Protocol (MCP) 服务器,允许外部 AI Agent 和工具以编程方式与您的 Zotero 文库交互。
- 端点:
http://localhost:23119/llm-for-zotero/mcp - 协议:JSON-RPC 2.0(MCP v2024-11-05)
- 方法:
initialize、tools/list、tools/call
这意味着您可以将任何兼容 MCP 的 AI Agent(如 Claude Desktop、Cursor、自定义 Agent)连接到您的 Zotero 文库,使用上述所有工具。
Agent 演示
多步骤工作流
Agent 可以串联多个工具完成复杂任务——例如查找论文、读取元数据、搜索相关文献并撰写摘要笔记。
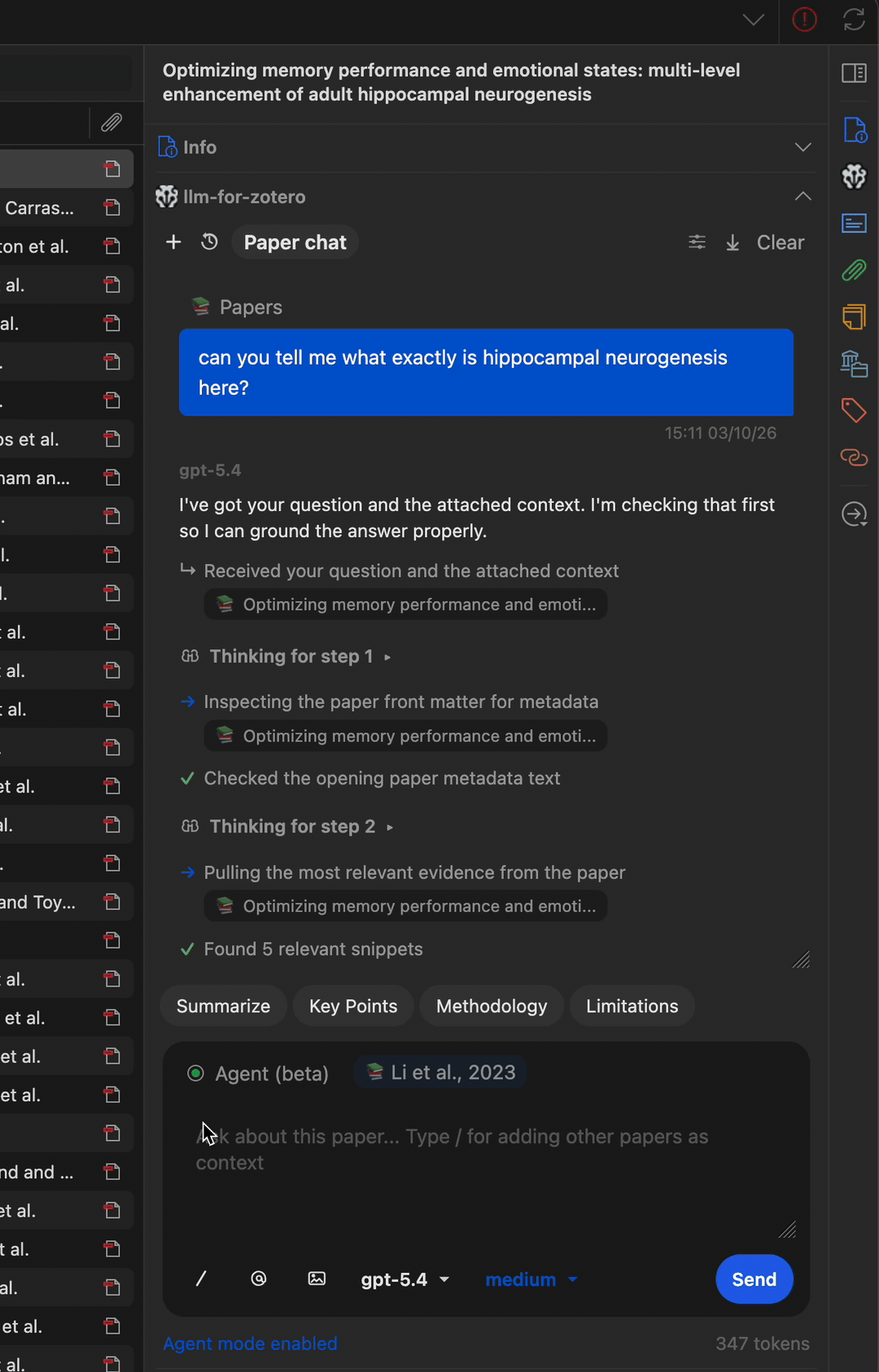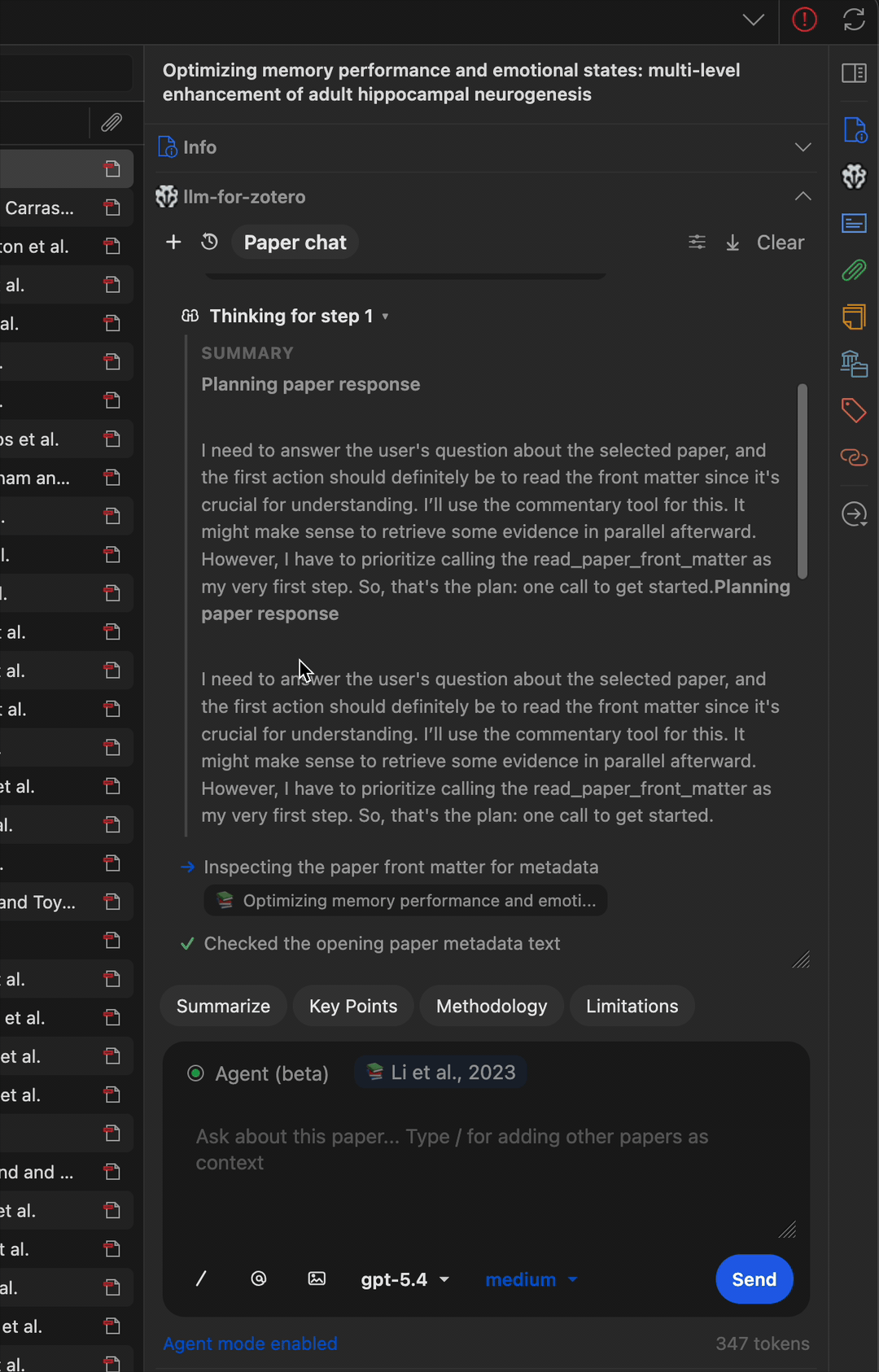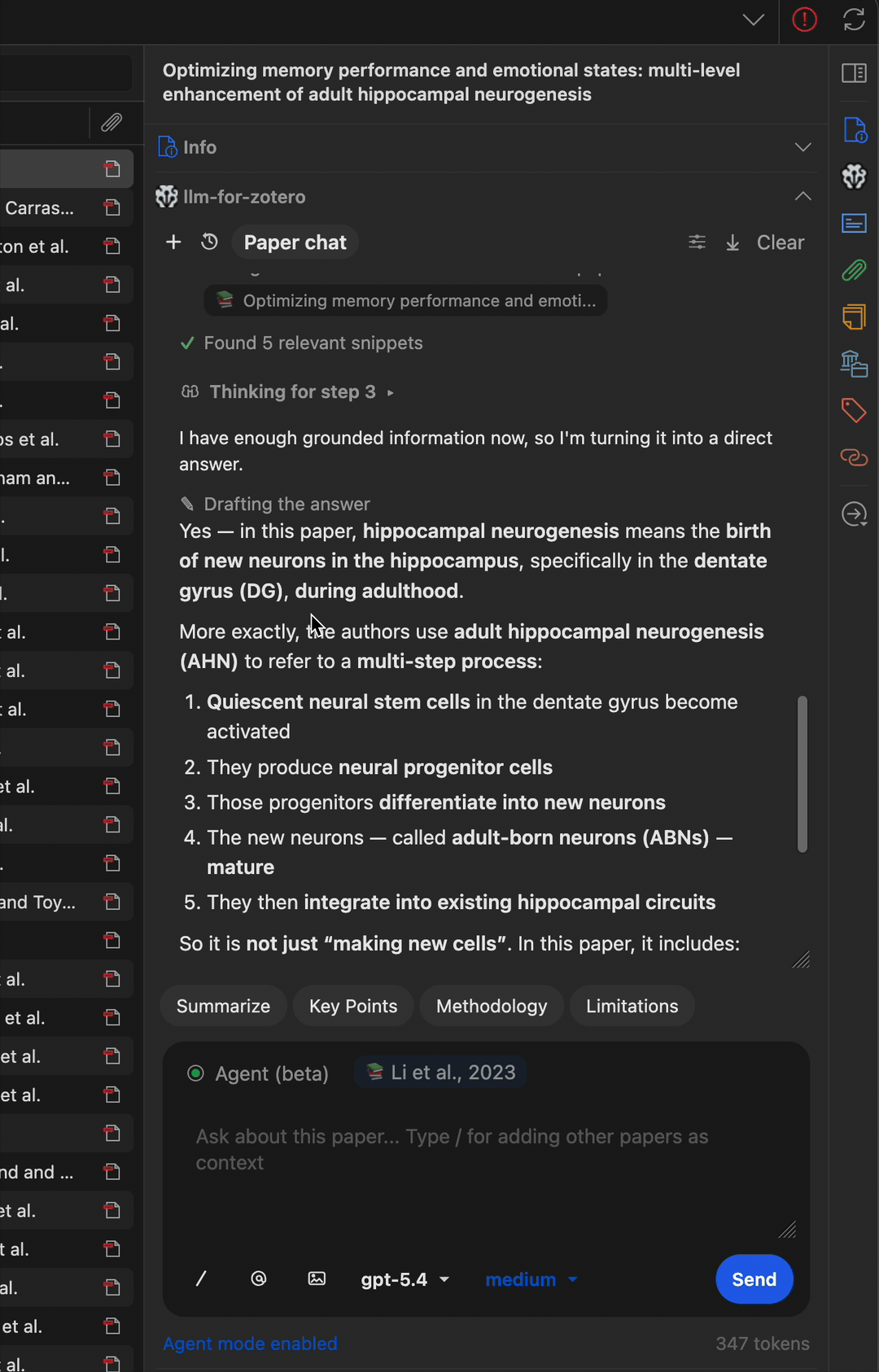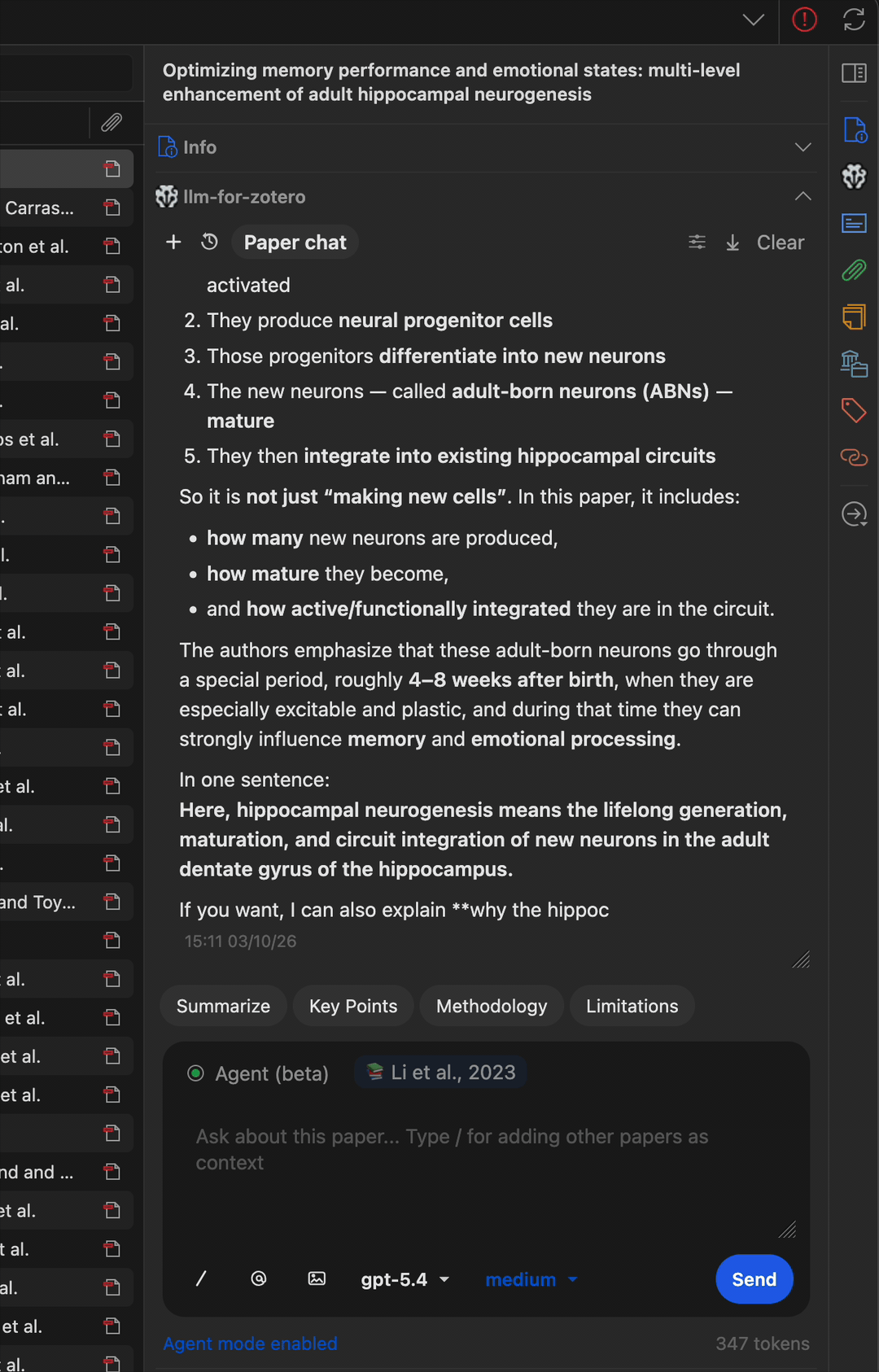
查找相关论文
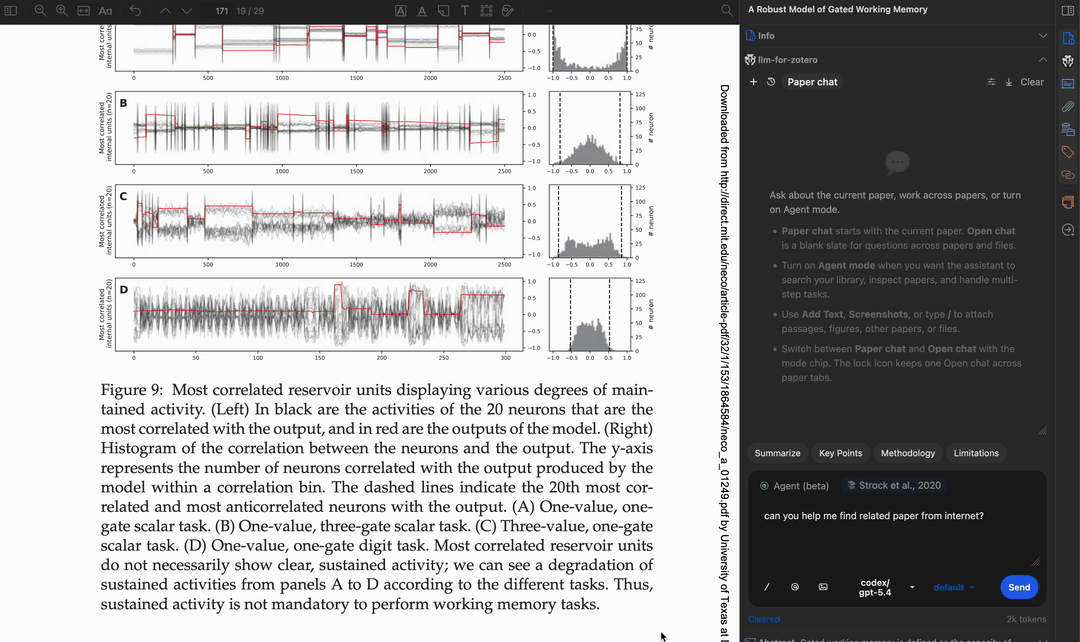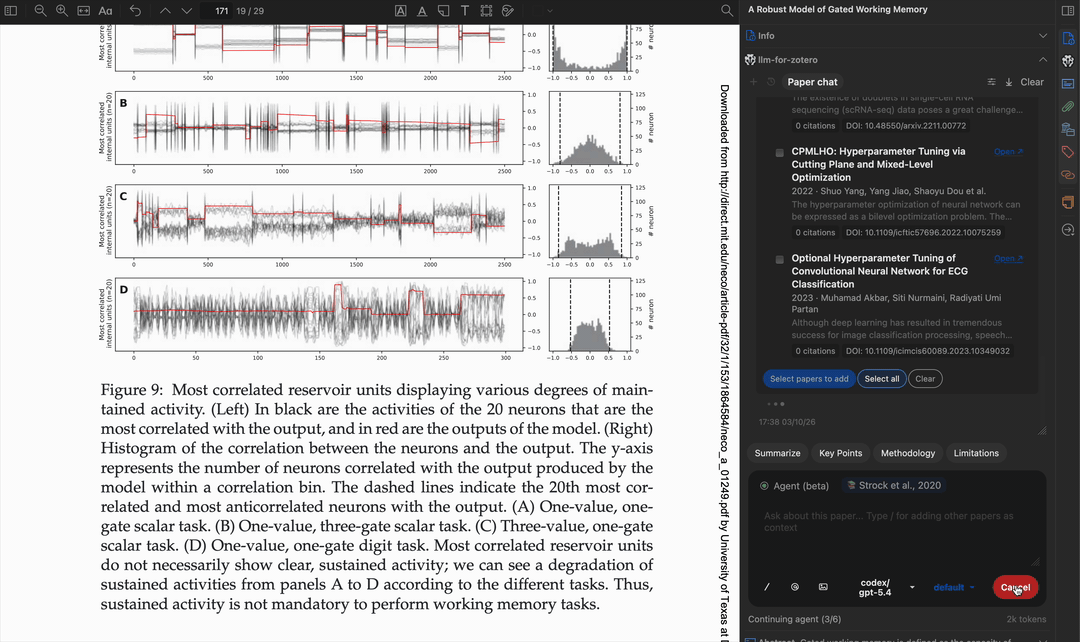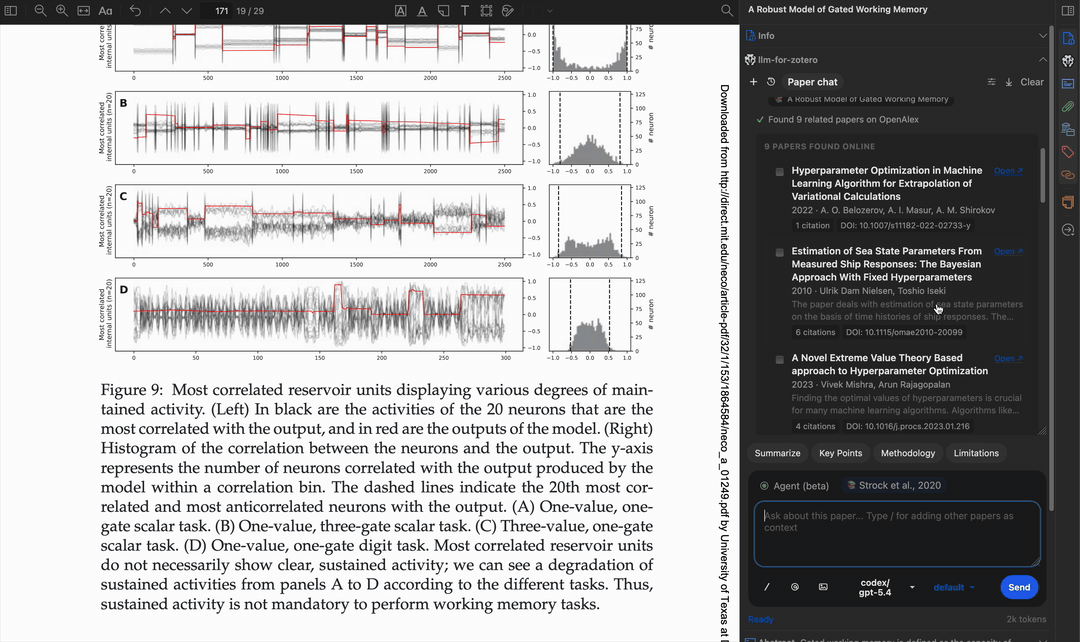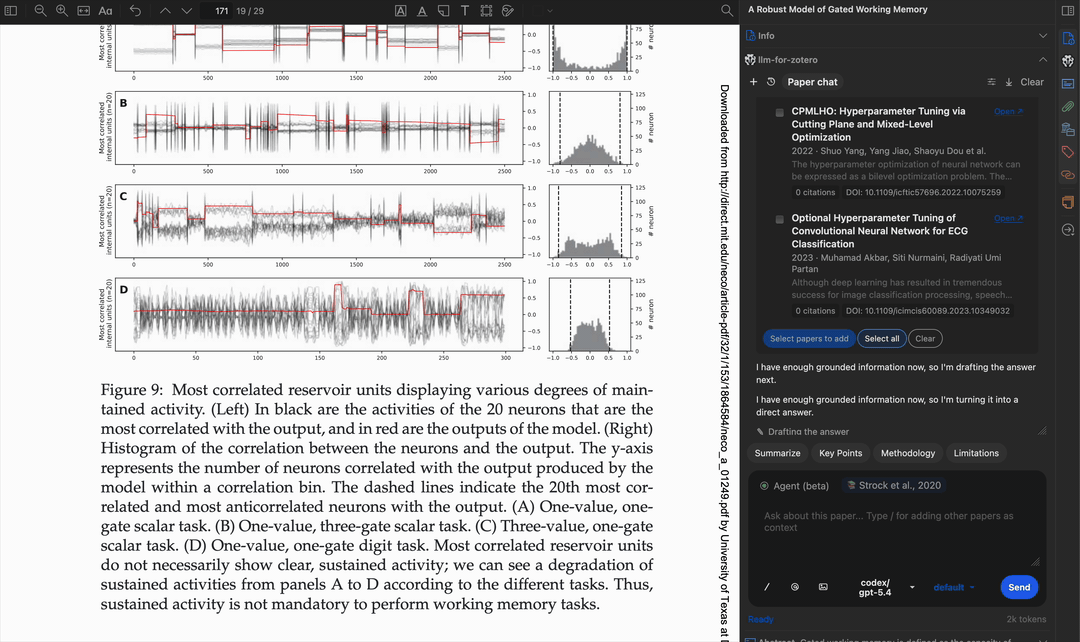
自动应用标签
撰写笔记
安全与审批
所有写入操作均通过人机协作确认流程:
- Agent 提出一批变更建议(如添加标签、编辑元数据)。
- 您在审批表单中查看拟定变更。
- 您可以在任何变更生效前选择批准、拒绝或修改。
- 如有问题,使用
undo_last_action进行撤销。 - 终端命令和文件操作同样需要明确审批后才会执行。
Skills 技能系统
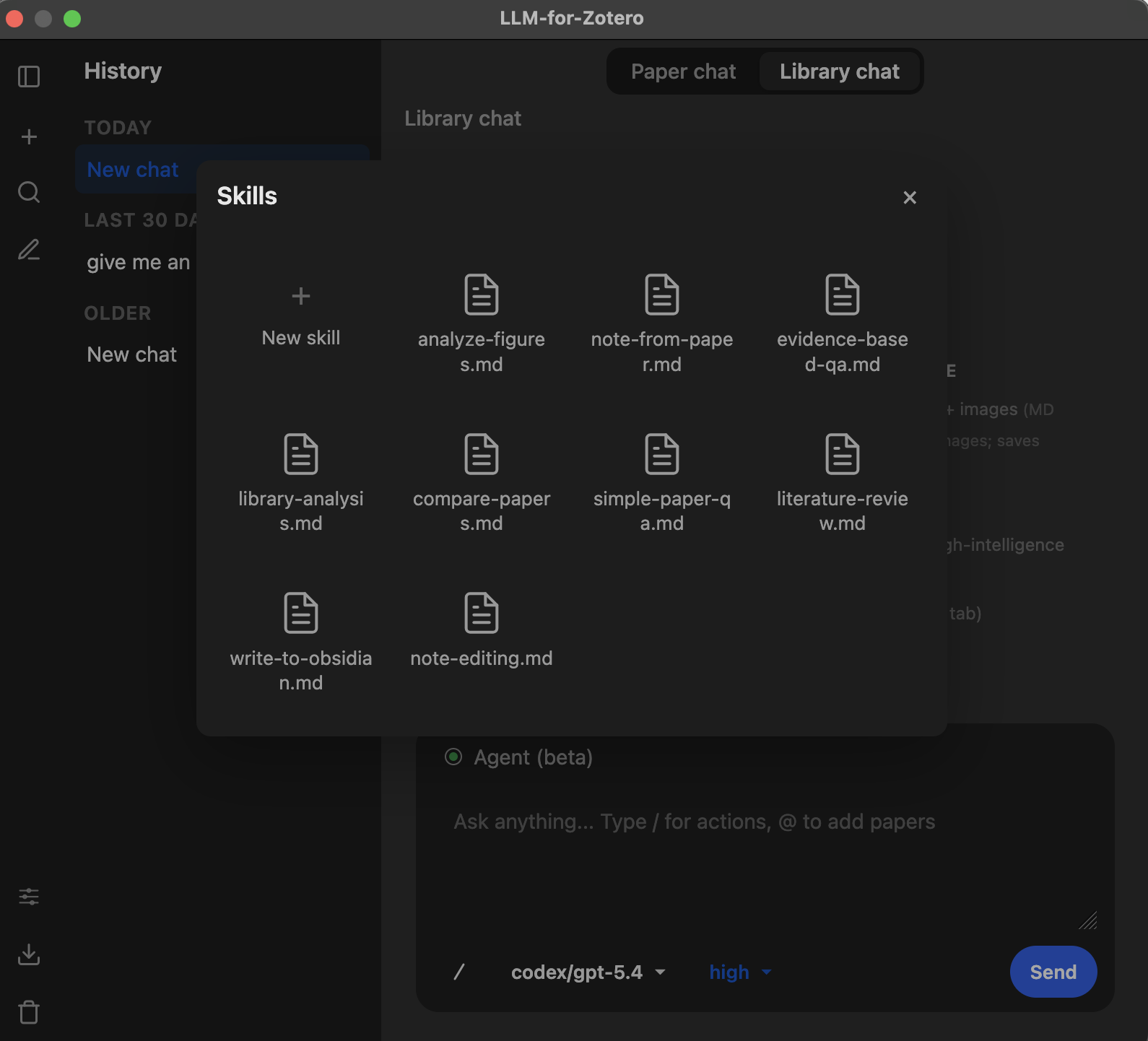
Skills(技能)是可自定义的引导文件,用于调整 Agent 处理不同类型请求的方式。每个技能是一个 Markdown 文件,包含正则表达式触发模式:当您的消息匹配某个技能的模式时,该技能的指令会自动注入 Agent 的系统提示词中,引导它使用最高效的工具和工作流来完成任务。
内置技能
插件内置 8 个技能,覆盖常见的研究工作流。首次运行时会自动复制到您的技能文件夹。
| 技能 | 触发场景 | 引导 Agent 执行的操作 |
|---|---|---|
simple-paper-qa | 关于论文的一般性问题(摘要、发现、作者、TLDR) | 读取论文一次后直接回答,避免不必要的检索调用 |
evidence-based-qa | 关于具体方法、结果、数据或论断的问题 | 先读取论文,再通过定向 search_paper 检索特定证据 |
analyze-figures | 按编号引用图表、表格或示意图 | 以 MinerU 为索引,直接从原始 PDF 裁剪精准图像并解读;表格则按结构化文本读取 |
compare-papers | 比较或对比多篇论文的请求 | 批量读取论文,再针对比较要点检索证据 |
library-analysis | 总结、分析或审计整个文库的请求 | 使用高效脚本遍历文库条目,而非通过上下文分页 |
literature-review | 文献综述或研究综合的请求 | 发现论文、深度阅读最相关的几篇,并按主题综合 |
write-note | 写作阅读笔记、Zotero 笔记或笔记目录 Markdown 文件的请求 | 生成带元数据、Pandoc 引用和可选图表复制的笔记 |
import-cited-reference | 导入当前 PDF 中引用文献的请求 | 提取参考文献,并将选中的引用论文导入 Zotero |
工作原理
- 在 Agent 模式下发送消息时,插件会将您的文本与每个技能的
match模式进行匹配。 - 如果技能中的任何一个模式匹配成功(OR 语义),该技能的指令会被注入 Agent 的系统提示词中。
- 多个技能可以同时激活——如果您的消息匹配了多个技能的模式。
- Agent 将这些指令作为工具选择和工作流的引导——技能教会 Agent 如何完成任务,而非定义它能做什么。
创建自定义技能
- 打开独立窗口(
Ctrl+Shift+L/ macOS:Cmd+Shift+L)。 - 点击顶部工具栏中的 Skills 图标打开技能管理面板。
- 点击 ”+ New skill” 按钮创建模板文件。
- 模板会在默认文本编辑器中打开,编辑以下三个关键部分:
---
id: my-custom-skill
match: /你的正则表达式模式/i
match: /另一个触发模式/i
---
当此技能匹配时,Agent 应遵循的指令。
描述工作流程、优先使用哪些工具以及任何约束条件。
- 保存文件。技能会立即加载——无需重启。
技能文件格式:
| 字段 | 必需 | 说明 |
|---|---|---|
id | 是 | 技能的唯一标识符 |
match | 是(至少一个) | 正则表达式模式,支持可选标志(i、g、m 等)。可重复——多个 match 行使用 OR 语义 |
| 指令正文 | 是 | 结束标记 --- 之后的 Markdown 文本。技能匹配时会注入 Agent 的系统提示词 |
管理技能
- 左键点击面板中的技能可在默认文本编辑器中打开编辑。
- 右键点击技能弹出上下文菜单,包含在文件系统中显示和删除选项。
- 技能以
.md文件形式存储在{Zotero数据目录}/llm-for-zotero/skills/中。 - 如果您删除了内置技能,它将在重启后保持删除状态——插件尊重您的选择。插件更新中新增的内置技能会自动添加,但不会恢复您已删除的技能。
.md 文件与他人分享自定义技能。将技能文件放入您的技能文件夹,在下次插件启动或在面板中创建/删除任何技能后即会被加载。WebChat 配置(ChatGPT & DeepSeek 网页同步)
WebChat 模式通过浏览器扩展将您的问题发送到 chatgpt.com 或 deepseek.com,再把回复实时流式传回 Zotero。它适合不想配置服务商 API 密钥、但想使用 ChatGPT 或 DeepSeek 网页端的场景。
前置条件
chatgpt.comWebChat 需要 ChatGPT 账号;deepseek.comWebChat 需要 DeepSeek 账号。- Chromium 内核浏览器,如 Chrome、Edge、Brave 或 Arc。
配置步骤
1. 下载浏览器扩展:
前往 github.com/yilewang/sync-for-zotero → Releases,下载最新的 extension.zip,解压到电脑上的文件夹。
2. 安装扩展(侧载):
- 打开浏览器,访问
chrome://extensions - 开启右上角的开发者模式
- 点击加载已解压的扩展程序,选择解压后的扩展文件夹
- “Sync for Zotero” 扩展应出现在扩展列表中
3. 配置插件:
打开 Zotero → 首选项 → llm-for-zotero:
| 设置项 | 值 |
|---|---|
| 认证模式 | WebChat |
| 模型 | chatgpt.com 或 chat.deepseek.com |
4. 开始对话:
在浏览器中打开 ChatGPT 或 DeepSeek 标签页并保持打开。在 Zotero 中,插件面板会显示 WebChat 指示器及连接状态点(绿色 = 已连接,红色 = 未检测到)。输入问题并发送即可。
WebChat 功能
- PDF 附件 — 右键点击论文标签切换 PDF 发送状态(紫色 = 发送,灰色 = 跳过)。
- 截图 — 使用截图按钮将图片上下文附加到消息中。
- 对话历史 — 点击时钟图标浏览和加载过往网页端对话。
- 退出 — 点击 “Exit” 按钮返回常规 API 模式。
技术说明
- 插件在 Zotero 内置端口(23119)上嵌入轻量级 HTTP 中继服务器,浏览器扩展通过轮询该中继交换查询和响应。
- WebChat 模式下禁用 Agent 模式、斜杠命令(
/)和引用选择器(@)。 - 推理/思考模式由网页端控制,而不是通过插件的推理切换按钮控制。
Codex 配置(ChatGPT Plus 订阅用户)
如果您拥有 ChatGPT Plus 订阅,可以通过 Codex CLI 登录,在插件中免单独 API 密钥使用 Codex 模型。
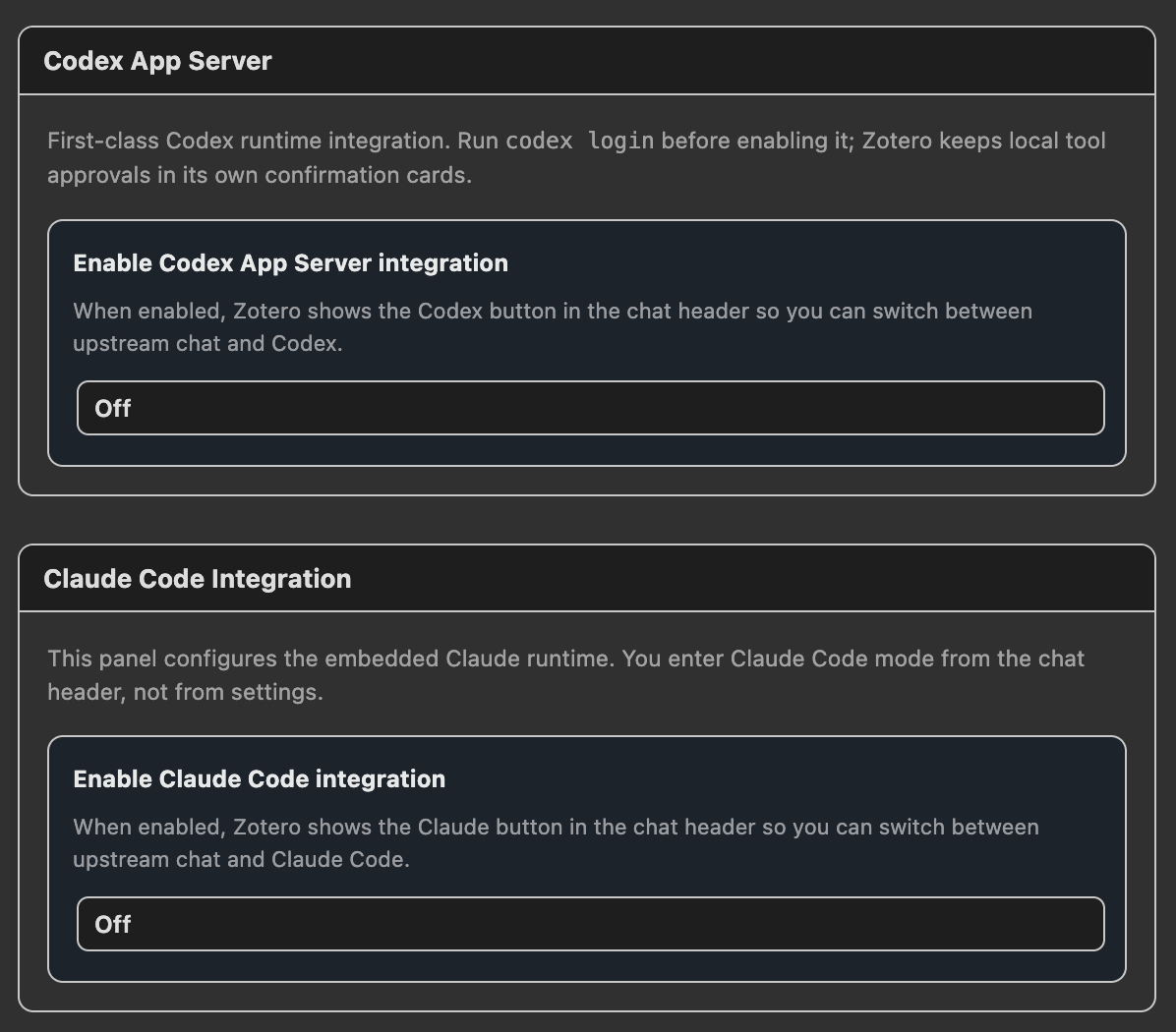
新用户应在 Agent 标签页中选择 Codex App Server。旧的 Codex Auth (Legacy) 路径仍可供现有用户使用,但计划在 app-server 验证稳定后逐步弃用。
- Codex App Server(推荐):启动本地
codex app-serverCLI,并通过 stdio 与其通信。这是第三方应用使用 Codex 的官方方式,也是新用户首选配置。该模式在 Agent 标签页中配置,并会在聊天标题栏显示独立的 Codex 按钮。 - Codex Auth (Legacy):直接调用 ChatGPT/Codex Responses 后端。现有用户暂时可以保留该配置,但新用户应选择
Codex App Server。
特别感谢 @jianghao-zhang 贡献最初的 Codex Auth 集成,以及 @boltma 设计 Codex App Server 集成。
配置步骤
1. 安装 Codex CLI(一次性操作):
# macOS / Linux(需要 Node.js 18+)
npm install -g @openai/codex
# macOS 替代方案(无需 Node.js)
brew install --cask codex
Windows 用户应在 PowerShell 或命令提示符中安装 Codex,而不是在 WSL 中安装,这样 Zotero MCP 才能使用 Windows 本地回环连接。
2. 登录 ChatGPT 账号:
codex login
浏览器窗口将自动打开——使用您的 ChatGPT Plus 账号登录。凭据保存至 ~/.codex/auth.json。
3. 在 Zotero 中启用 Codex App Server:
打开 Zotero → 首选项 → llm-for-zotero → Agent 标签页:
| 设置项 | 推荐值 |
|---|---|
| 启用 Codex App Server 集成 | On |
| 模型 | 例如 gpt-5.4 |
| 推理等级 | auto、low、medium、high 或 xhigh |
点击测试连接,验证 Zotero 能否启动 codex app-server,然后在聊天标题栏点击 Codex 按钮进入 Codex 对话系统。
Codex App Server 与 Claude Code 是 Agent 标签页中的互斥运行时模式。启用其中一个之前,需要先关闭另一个。
仍需旧方式的现有用户可以打开 AI Providers 标签页,选择 Codex Auth (Legacy),API 地址保持 https://chatgpt.com/backend-api/codex/responses,模型名称保持不变,例如 gpt-5.5。
Codex Auth (Legacy) 技术说明
- 从
~/.codex/auth.json(或$CODEX_HOME/auth.json)读取本地凭据。 - 遇到 401 响应时自动尝试刷新 Token。
- 支持本地 PDF 内容定位和截图/图像输入。
- Legacy 直连模式暂不支持嵌入向量和
/files上传流程。
Claude Code 配置(实验性)
Claude Code 模式会将 Claude Code 作为 Zotero 内部独立的对话系统运行。它复用熟悉的侧栏和独立窗口界面,但拥有独立的对话历史、paper / open 范围状态、模型/推理设置、权限语义、斜杠命令和项目技能。
前置条件
- 已安装并可正常运行 Claude Code CLI。请参考官方 Claude Code 安装、快速开始 和 认证 文档。
claude命令必须位于PATH中,并且已经完成登录认证。请先在终端运行claude;如果 Claude Code 未安装、不在PATH中或尚未登录,Zotero 侧 Claude Code 模式无法工作。- 已安装 Node.js 和 npm,用于运行配套桥接适配器。
1. 安装并验证 Claude Code
按照 Anthropic 官方说明安装 Claude Code,然后运行:
claude
继续之前,请先完成 Claude Code 中的登录或认证提示。
2. 启动 Zotero Claude 桥接服务
Claude Code 模式依赖配套桥接仓库 cc-llm4zotero-adapter。桥接服务不会替代 Claude Code;它只是把 Zotero 连接到您本地的 Claude Code 运行时。
git clone https://github.com/jianghao-zhang/cc-llm4zotero-adapter.git
cd cc-llm4zotero-adapter
npm install
npm run build
npm run serve:bridge
在另一个终端中检查桥接服务是否存活:
curl -fsS http://127.0.0.1:19787/healthz
如果您使用 macOS,并希望桥接服务在后台长期运行,可以在适配器仓库中安装 LaunchAgent:
./scripts/install-macos-daemon.sh
常用后台服务命令:
npm run daemon:status
npm run daemon:start
npm run daemon:stop
npm run daemon:restart
npm run daemon:uninstall
如果 Claude Code 模式无响应,请先重启桥接服务,并重新检查 /healthz。/healthz 通过只说明适配器正在运行;它不能证明底层 claude CLI 已安装、已认证或配置正确。
3. 在 Zotero 中启用 Claude Code
打开 Zotero → 首选项 → llm-for-zotero → Agent 标签页。
| 设置项 | 推荐值 |
|---|---|
| 启用 Claude Code 集成 | On |
| Bridge URL | http://127.0.0.1:19787 |
| Claude Config Source | default — user + project + local |
| Permission Mode | safe |
| Default Model | sonnet |
| Default Reasoning | auto |
除非您已经熟悉 Claude Code 的设置层级,否则建议保持 Claude Config Source 为 default。在 default 下,Claude Code 会同时使用您的用户级设置、Zotero 管理的项目级设置和每个对话的本地设置。
启用集成后,在聊天标题栏点击 Claude Code 按钮即可进入 Claude Code 模式。Claude 对话系统与上游聊天和内置 Agent 相互隔离,因此切换模式时会打开对应系统自己的对话历史,而不会混合不同运行时的 transcript。
4. 准备 Claude 项目技能与命令
Zotero 会在您的用户目录下创建 Claude 运行时根目录,通常类似:
~/Zotero/agent-runtime/profile-.../
在该运行时根目录中,共享 Claude 项目资产位于:
CLAUDE.md
.claude/settings.json
.claude/skills/
.claude/commands/
每个 Claude 对话还会在运行时 scopes/ 树下拥有自己的本地 .claude 文件夹,因此单个对话的本地覆盖不会泄漏到其他聊天。您可以手动把共享 Claude 技能放入 .claude/skills/ 或 .claude/commands/,但通常更简单的做法是直接让 Claude Code 在 Zotero 项目级 Claude 配置中创建或安装技能。
非 Anthropic 原生 Claude Code 配置
Zotero UI 中显示的 opus、sonnet、haiku 是能力层级,不要求底层一定是 Anthropic 托管模型。如果您通过兼容的 provider 层或代理路由 Claude Code,请在 Claude Code 自身配置中完成;Zotero 只负责选择层级并把请求转发给桥接服务。
MinerU PDF 解析
MinerU 是一款先进的 PDF 解析引擎,可从 PDF 中提取高保真 Markdown,同时保留表格、公式、图表和复杂版式——这些内容在标准文本提取中往往会被破坏。
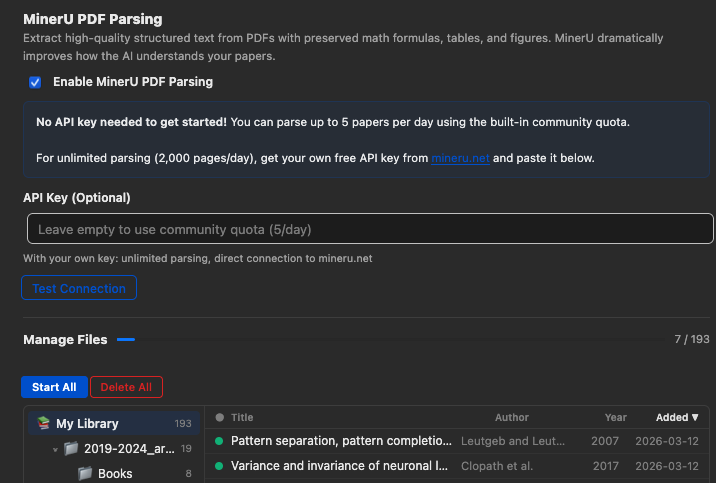
解析结果会缓存在本地,并在后续对话中复用。启用 Auto-parse newly added items 后,新添加的 PDF 附件会在进入 Zotero 文库时发送给 MinerU 解析。如果不启用自动解析,也可以在 Manage Files 面板中手动解析选中或过滤后的 PDF。
MinerU 缓存是为 AI 准备的,不是第二套给人阅读的 PDF 界面。Zotero 仍然是阅读、标注和管理原始 PDF 的地方。MinerU 会生成模型更容易使用的结构化旁路材料:干净的 Markdown、章节范围、页码提示、表格、公式和提取出的图像资源。这样可以尽量不打扰原有 Zotero UI,同时为助手提供比普通 PDF 文本提取更好的论文上下文。
对于图像相关的问题,MinerU 充当定位每张图的索引,而模型实际看到的图像则是直接从原始 PDF 裁出的精准裁剪;详见精准图像提取。
启用方法
- 打开 Zotero → 首选项 → llm-for-zotero。
- 找到 MinerU 部分,勾选启用 MinerU。
- 保持云端模式,或勾选 Use local MinerU server 使用本地模式。
- 云端模式下,可选填入您自己的 MinerU API 密钥。
- 本地模式下,运行自托管
mineru-api服务;除非服务使用了其他地址,否则保持默认 Base URLhttp://127.0.0.1:8000。 - 如果希望新导入的 PDF 自动解析,请勾选 Auto-parse newly added items。之后将 PDF 添加或导入 Zotero 文库,插件会通过 MinerU 解析新添加的 PDF 附件,并缓存结果供后续对话复用。
使用自有 API 密钥
MinerU 可通过内置 API 在没有密钥的情况下启动,但强烈建议配置个人密钥。内置 API 可能在 2026 年 6 月 1 日 之后不再受支持。
获取免费个人密钥:
- 前往 mineru.net 注册账号。
- 在账号设置中生成 API 密钥。
- 将密钥粘贴到 Zotero → 首选项 → llm-for-zotero → MinerU。
- 点击测试连接以验证。
提供个人 API 密钥后,插件将直接调用 https://mineru.net/api/v4。
使用本地 MinerU 服务
本地 MinerU 服务支持由 @renyong18 在 PR #152 中贡献。
本地模式会通过 POST /file_parse 将 PDF 发送到自托管 mineru-api 服务,并把返回的 ZIP 输出保存为与云端解析相同的本地缓存格式。默认 Base URL 为 http://127.0.0.1:8000。
本地模式前置条件:
- 安装 MinerU 并运行
mineru-api;安装方式请参考 MinerU 文档。 - 确保所需模型已经下载。
mineru-api会在首次请求时懒加载模型,因此启动服务后第一次解析,或切换 backend 后第一次解析,通常会比稳定状态更慢。
本地设置中可以选择 Backend:
pipeline(默认)— 通用、多语言、对 CPU 更友好。vlm— 基于 VLM,对中英文文档准确率高,需要 GPU。hybrid— 较新的高准确率混合流程,支持多语言,需要本地算力。
Test Connection 只检查服务进程是否在 /health 响应;它不能保证所有模型已经预热完成。
使用默认 127.0.0.1 地址时,PDF 会留在本机。如果您把 Base URL 改为局域网或远程服务器,PDF 会被发送到该服务器。
暂停 / 取消限制: mineru-api 没有提供取消或 DELETE 端点,只提供 POST /file_parse、POST /tasks、GET /tasks/{id}、GET /tasks/{id}/result 和 GET /health。点击 Pause 后,插件会暂停队列并中止 HTTP 等待,但服务器上已经开始的解析仍会继续运行直到结束,GPU/CPU 计算不会立刻停止。如果需要立即中止,例如想立刻切换 backend,请自行重启 mineru-api 进程。
管理 MinerU 缓存
MinerU 首选项标签页包含 Manage Files 面板,用于维护已解析的 PDF 缓存:
- 按文集、标签、标题、作者、年份和添加日期浏览已缓存与未缓存的 PDF。
- 对所有可见文件、过滤后的文件或选中的文件开始解析。
- 当元数据或文件发生漂移时,修复本地 MinerU 缓存和已同步的缓存包。
- 从管理器中删除全部、过滤后、选中或单个条目的缓存。
- 使用标签过滤器,包括 Zotero 自动标签,选择哪些论文参与批量操作。
自动缓存管理是事件驱动的。插件监听 Zotero 条目添加事件,识别普通论文条目下的 PDF 附件或独立 PDF 附件,并在处理前短暂等待,让 Zotero 完成文件导入。如果 Zotero 条目已经出现,但 PDF 文件路径或父条目的附件列表还没准备好,队列会按短延迟重试,而不是立刻判定失败。已删除的附件会从队列移除,已经有缓存的 PDF 会被跳过。
自动队列和批量解析使用同一套过滤规则。它会跳过已经有本地 MinerU 缓存或可用同步包的 PDF,避免重复入队,并通过 MinerU 状态点显示 ready、processing 或 failed。普通元数据修改不会反复重解析已经完成的 PDF;modify 事件主要用于恢复正在处理、失败或文件尚未就绪的情况。
解析成功后,插件会在 Zotero 数据目录下的 llm-for-zotero-mineru/<attachmentId>/ 写入缓存。核心文件包括 full.md、manifest.json、content_list.json、提取出的图像等资源,以及记录来源的 _llm_source.json。manifest.json 是为 AI 访问设计的:它把章节标题映射到字符范围、页码提示和章节级图表,让 Agent 可以按问题读取 full.md 中相关片段,而不是每次都加载整篇论文。
写入 MinerU 缓存后,插件会清理该 PDF 旧的内存文本缓存和嵌入缓存。下一次提问会使用 MinerU 质量的文本块,并基于更好的解析文本重新生成检索数据。
高级解析过滤器可以在自动解析或批量解析前跳过文件:
- Skip files over N pages 控制 Start All、Start Filtered、Start Selected 和自动解析使用的最大页数。默认值为 100 页。
- Exclude PDFs by Filename 支持逗号分隔的子字符串,或用
/slashes/包裹的正则表达式,可用于排除翻译副本、补充材料或其他不希望自动解析的文件。
如果启用 Sync MinerU cache with Zotero file sync,插件可以创建包含 full.md、manifest.json、content_list.json 和提取资源的配套 ZIP 附件。同步是可选功能,默认关闭。已有本地缓存只会在您从 MinerU 标签页主动请求时同步;同步包也可以在需要时恢复缺失的本地缓存。修复流程会验证同步包的元数据和内容哈希,清理同一来源 PDF 的重复同步包,移除孤立的本地缓存,并从可用的同步 ZIP 中恢复本地缓存文件夹。
精准图像提取

当 Agent 模式回答关于某张图的问题,或保存讨论该图的笔记时,它会直接从原始 PDF 中裁剪出精准的高分辨率图像,仅将 MinerU 缓存用作索引。 只需提问 “图 3 展示了什么?”,Agent 便会从 MinerU 解析中定位该图,从原始 PDF 页面裁出干净的图像,并连同图注和各子图一起进行解读。
这与图表解读不同——后者由您自己截图。 在这里,Agent 会替您查找并裁剪图像,而保存图像到笔记时嵌入的也正是这些裁剪结果。
| 步骤 | 说明 |
|---|---|
| 以 MinerU 为索引 | MinerU 解析提供图像标签、图注和页码提示。 |
| 从 PDF 裁剪 | 图像直接从原始 PDF 页面裁出,而非使用 MinerU 自身的图片,因此标签和子图保持清晰。 |
| 缓存与复用 | 每张裁剪图都会针对 PDF 计算指纹,并被后续问答和笔记复用;当源文件变化时缓存会自动修复。 |
| 嵌入笔记 | 保存图像笔记时,会以  形式嵌入裁剪图,并自动作为 Zotero 附件导入。 |
须知:
- 无需配置。 裁剪由插件按平台下载并管理的小型提取运行时生成,您无需自行安装 Python 或任何其他工具。
- 只提取图像,不含表格。 表格会从 MinerU 解析中以结构化 Markdown 文本读取,因此图像提取会刻意跳过表格。
- 需要 MinerU 缓存。 图像提取需先由 MinerU 解析该论文。若无缓存,Agent 会回退到仅使用图注和上下文文本,并明确告知无法提取图像。
隐私与数据流
- 标准服务商模式下,论文内容和用户消息会发送给您配置的模型服务商。
- 本地模型模式下,请求会发送到您配置的本地 OpenAI 兼容端点。
- WebChat 模式下,请求会通过浏览器扩展转发到
chatgpt.com或chat.deepseek.com。 - 云端 MinerU 模式下,被自动解析或手动解析选中的 PDF 会发送给 MinerU。
- 本地 MinerU 模式下,被自动解析或手动解析选中的 PDF 会发送到您配置的本地或远程
mineru-api服务。 - 对话历史和缓存的论文上下文由插件存储在本地。
- Agent 模式的写入操作会尽可能通过可审阅动作和会话内撤销机制处理。
故障排查
| 现象 | 检查项 |
|---|---|
| 测试连接失败 | 确认基础 URL、API 密钥、模型名称和服务商协议。 |
| 助手看不到论文 | 重新打开 PDF 标签页,然后发送新消息,让插件重建上下文。 |
| WebChat 显示红点 | 保持 ChatGPT 或 DeepSeek 标签页打开,并确认 Sync for Zotero 扩展已加载。 |
| Codex App Server 失败 | 运行 codex login,确认 codex 位于 PATH 中,然后再次点击测试连接。 |
| Claude Code 模式卡住 | 重启桥接服务,并检查 curl -fsS http://127.0.0.1:19787/healthz。 |
| MinerU 解析失败 | 云端模式下添加个人 MinerU API 密钥;本地模式下确认 mineru-api 服务能在 /health 响应,然后重新尝试测试连接。 |
如果遇到 Bug 或难以判断的问题,请在 GitHub 上 提交 Issue。
路线图
- Agent 模式(beta)
- MinerU PDF 解析
- GitHub Copilot 认证
- WebChat 模式(ChatGPT 网页同步)
- 独立窗口模式(#78)
- 文件笔记(Obsidian、Logseq、任意 Markdown 目录)
- Claude Code 集成
- Codex App Server 集成
- 自定义技能
- 本地 MinerU 支持
- 跨设备同步(MinerU 缓存)
- Agent 记忆系统
常见问题
是否免费使用?
是的,插件完全免费且开源(AGPL v3)。您只需为调用所选服务商的 API 付费。使用 Codex App Server 时,ChatGPT Plus 订阅用户无需单独 API 密钥。
是否支持本地模型?
支持——任何提供 OpenAI 兼容 HTTP API 的模型均可使用,包括通过 Ollama、LM Studio、vLLM 等工具本地部署的模型。在设置中填写本地 API 地址和模型名称即可。
我的数据是否会用于训练模型?
插件本身不会训练模型。数据处理取决于您选择的后端:配置的 API 服务商、本地模型、WebChat、Codex、Claude Code 或 MinerU。
能否同时使用多个模型?
可以。配置最多 10 个服务商组,每组包含多个模型,通过模型选择器在对话中随时切换。
上下文检索是如何工作的?
首条消息会加载论文全文作为上下文,后续问题使用混合检索(BM25 + 嵌入向量搜索)并结合多样性优化,定位最相关段落,保持响应快速准确。
如何报告 Bug 或提交功能请求?
请在 GitHub 上 提交 Issue。
贡献与支持
欢迎贡献!无论是 Bug 反馈、功能请求还是 Pull Request——欢迎在 GitHub 上提交 Issue 或 PR。
如果本插件对您有帮助,欢迎:
