LLM for Zotero


llm-for-zotero 是一款免费的开源 Zotero 插件,可将大型语言模型直接集成到 PDF 阅读器中。与需要将 PDF 上传到网页端的工具不同,本插件让您无需离开 Zotero 即可与论文对话。它静静地驻留在阅读器侧栏——随时待命的研究助手。
就任意打开的 PDF 提问,回答基于论文内容并附带可点击的引用跳转。
OpenAI、Anthropic、Google Gemini、DeepSeek、本地模型——使用任何您偏好的 LLM。
自主管理文库、执行终端命令、访问本地文件的智能代理——所有变更均需您审批。
使用高保真 PDF 解析,完整保留表格、公式、图表和复杂版式。
最新更新
- Agent 模式(Beta):LLM-for-Zotero 现在可以作为自主 Agent 在您的 Zotero 文库中工作。
- 终端与文件访问:Agent 可执行终端命令并读写本地文件——如同 Zotero 内置的编程 Agent。
- MCP 服务器:外部 AI Agent 可通过内置的 Model Context Protocol 服务器连接 Zotero。
- Codex 认证:ChatGPT Plus 订阅用户可以使用
gpt-5.4等 Codex 模型,无需单独的 API 密钥。 - MinerU PDF 解析:高保真提取现可更准确地保留表格、公式和图表。
- 更名:插件现已更名为
llm-for-zotero。
安装
-
下载最新的
.xpi安装包 前往 Releases 页面 下载最新的.xpi文件。 -
在 Zotero 中安装插件 打开 Zotero →
工具→附加组件→ 点击齿轮图标 → 从文件安装附加组件 → 选择.xpi文件。 -
重启 Zotero 重启 Zotero 完成安装。插件会在每次启动时自动检查更新。
配置
打开 首选项 → 切换到 llm-for-zotero 标签页。
- 选择您的服务商(如 OpenAI、Gemini、DeepSeek)。
- 填写 API 基础 URL、API 密钥 和模型名称。
- 点击 测试连接 以验证配置。

支持的服务商与协议
插件原生支持以下五种服务商协议:
| 协议 | 说明 | 主要功能 |
|---|---|---|
responses_api |
OpenAI Responses API | 流式输出、工具调用、文件上传、多模态 |
openai_chat_compat |
OpenAI 兼容聊天 API | 流式输出、工具调用、多模态 |
anthropic_messages |
Anthropic Messages API | 流式输出、工具调用、多模态 |
gemini_native |
Google Gemini API | 流式输出、工具调用、多模态 |
codex_responses |
ChatGPT/Codex 认证 | ChatGPT Plus 直连,无需单独 API 密钥 |
支持的模型
| API 地址 | 模型 | 推理等级 | 备注 |
|---|---|---|---|
https://api.openai.com/v1/responses |
gpt-5.4 | default, low, medium, high, xhigh | 支持 PDF 上传 |
https://api.openai.com/v1/responses |
gpt-5.4-pro | medium, high, xhigh | 支持 PDF 上传 |
https://api.deepseek.com/v1 |
deepseek-chat | default | |
https://api.deepseek.com/v1 |
deepseek-reasoner | default | |
https://generativelanguage.googleapis.com |
gemini-3-pro-preview | low, high | |
https://generativelanguage.googleapis.com |
gemini-2.5-flash | medium | |
https://generativelanguage.googleapis.com |
gemini-2.5-pro | default, low, high | |
https://api.moonshot.ai/v1 |
kimi-k2.5 | default |
任何提供 OpenAI 兼容 HTTP API 的模型均可使用,包括通过 Ollama、LM Studio 或 vLLM 本地部署的模型。
多服务商配置
您可以配置最多 10 个服务商组,每组包含多个模型,从而:
- 用多模态模型解读图表,用文本模型生成摘要。
- 通过多个模型交叉验证答案,获得更全面的理解。
- 在对话中随时通过模型选择器切换模型。
推理等级与超参数
对于支持的模型,您可以为每次请求设置推理等级:default、low、medium、high 或 xhigh,用于控制模型在回答前的思考深度。
其他可调参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| Temperature | 控制输出随机性(0 = 确定性,2 = 创意性) | 1.0 |
| 最大输出 Token 数 | 限制模型回复长度 | 2048 |
| 输入 Token 上限 | 限制发送给模型的上下文大小 | 模型默认值 |
| 系统提示词 | 每次请求前置的自定义指令 | — |
使用指南
- 在 Zotero 阅读器中打开任意 PDF。
- 点击右侧工具栏中的 LLM 助手图标以打开侧栏。
- 输入问题,例如“这篇论文的主要结论是什么?”
首条消息会将整篇论文作为上下文加载,后续问题则通过检索定位相关段落,保持对话快速且精准。
对话模式
插件支持三种对话模式:
| 模式 | 说明 |
|---|---|
| 论文对话 | 针对当前打开的 PDF 进行对话,上下文来自该论文。 |
| 全局对话 | 覆盖整个文库的对话,不限定于某篇论文。 |
| 笔记对话 | 编辑 Zotero 笔记时进行对话,以笔记内容为上下文。 |
界面控件
- 模型选择器 — 在对话中随时切换已配置的模型。
- 推理等级选择器 — 为当前请求选择推理深度。
- 字体缩放 — 将侧栏字体大小从 80% 调整至 180%。
- 自动滚动 — 自动滚动至最新消息。
- Token 用量 — 实时显示输入、输出及推理 Token 消耗。
带引用跳转的有据答案
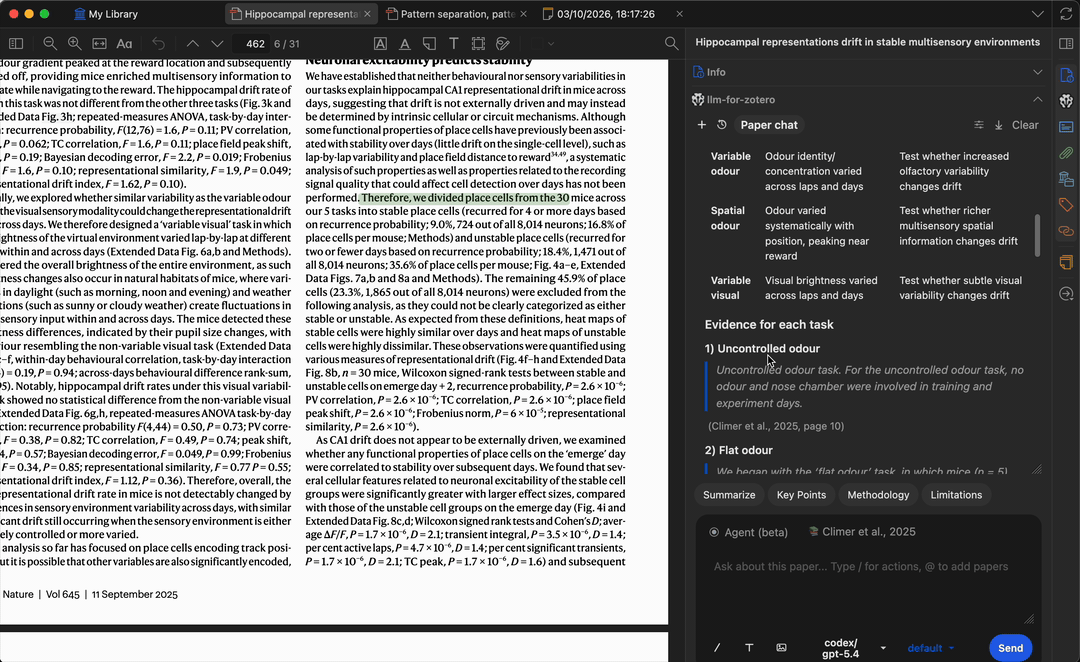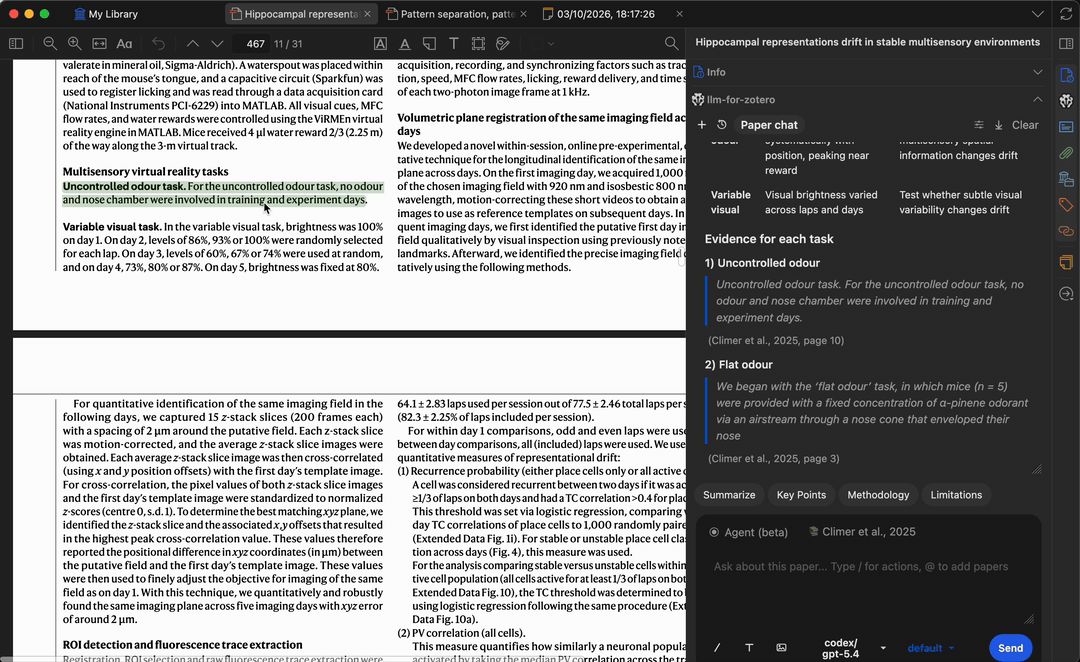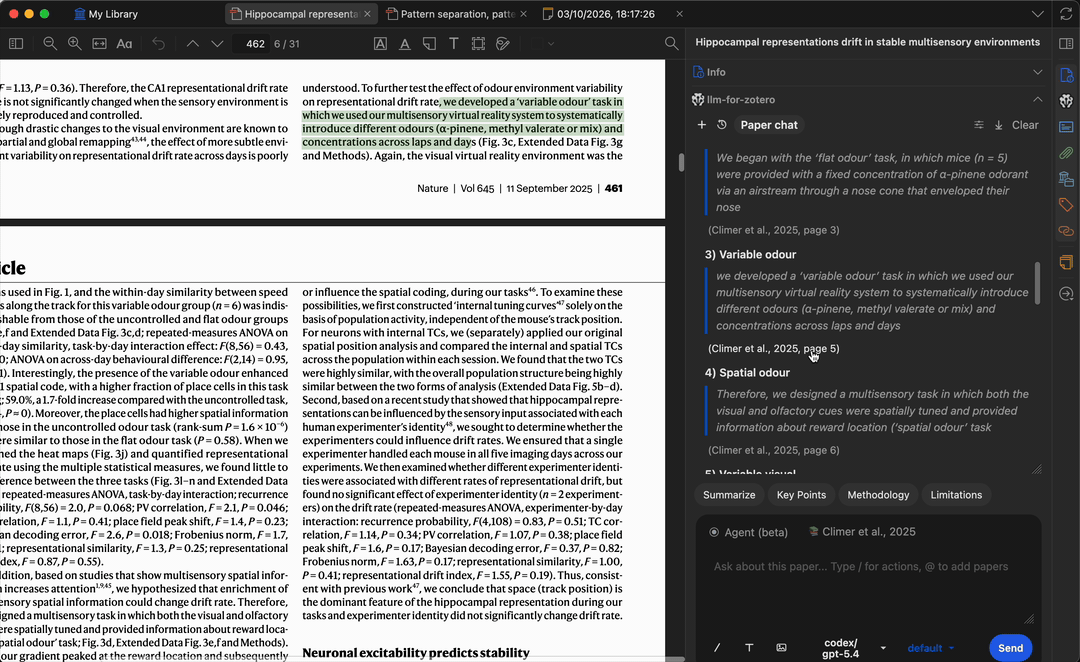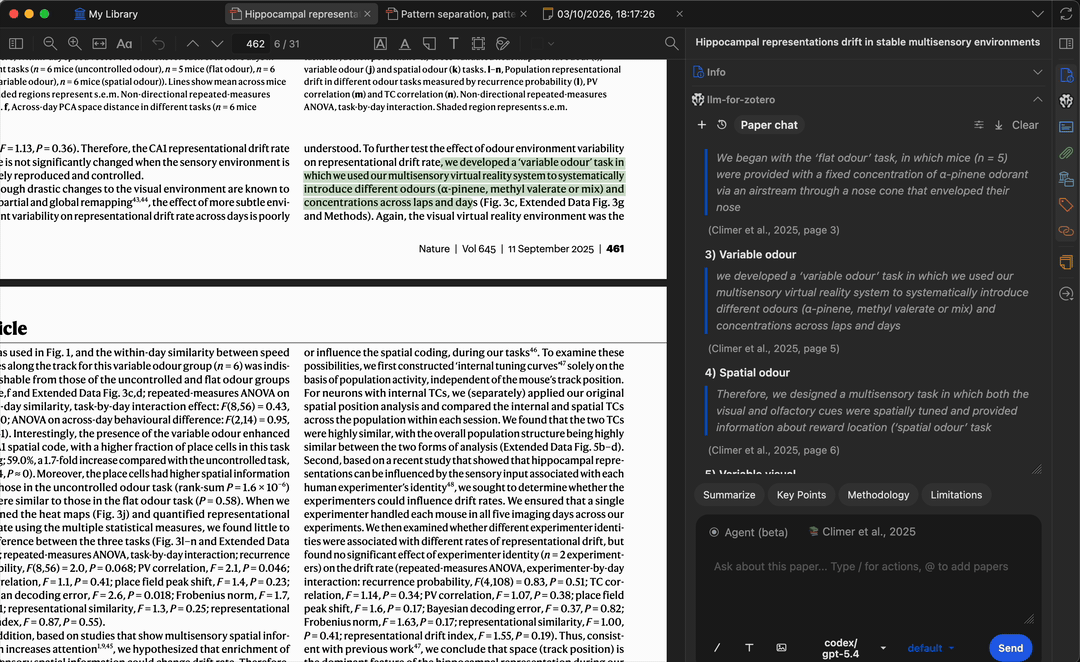
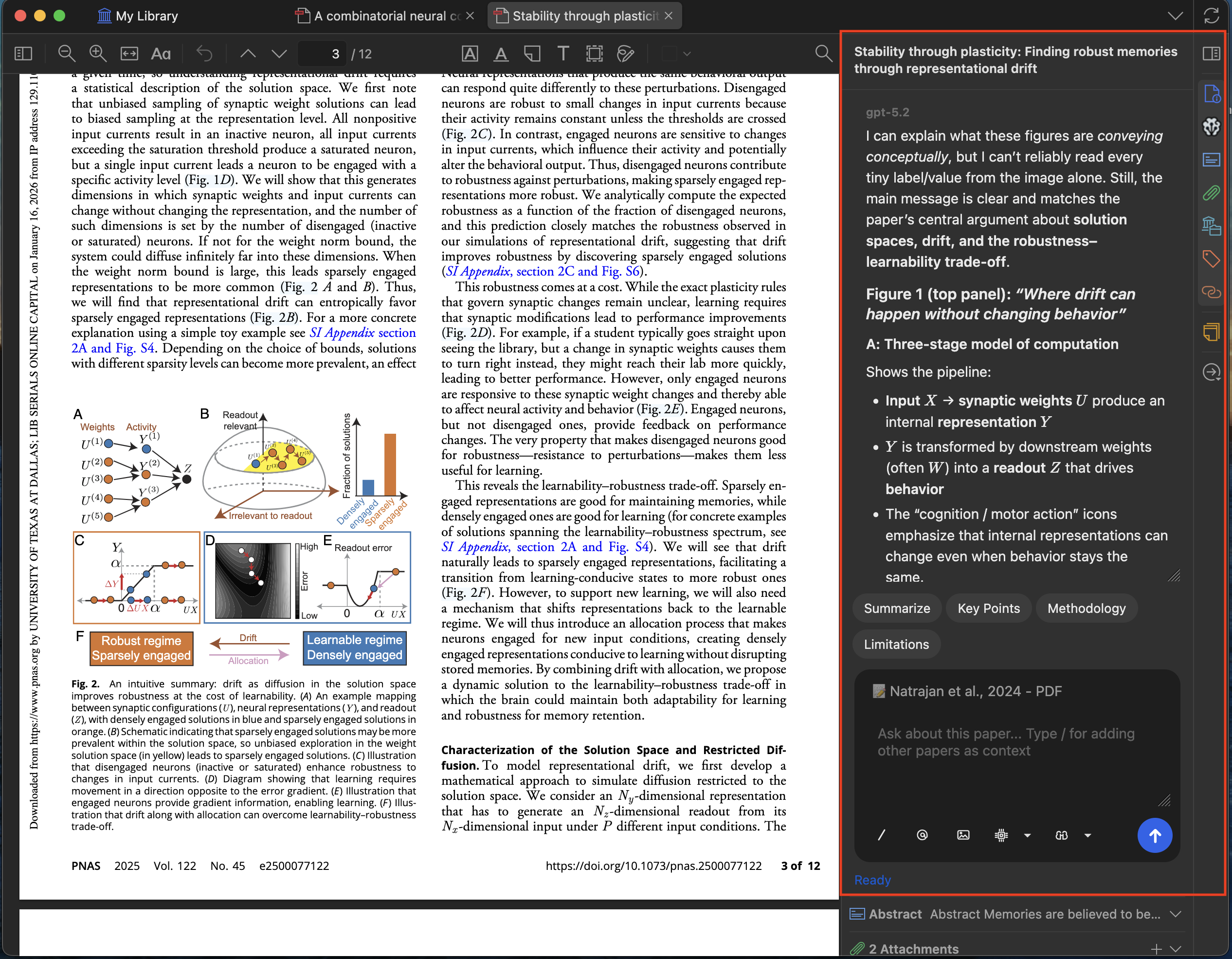
提问时,模型会生成基于论文内容的答案,每条结论均附有引用——点击即可跳转到 PDF 中的原始段落,方便核实答案并快速定位相关章节。
论文摘要生成
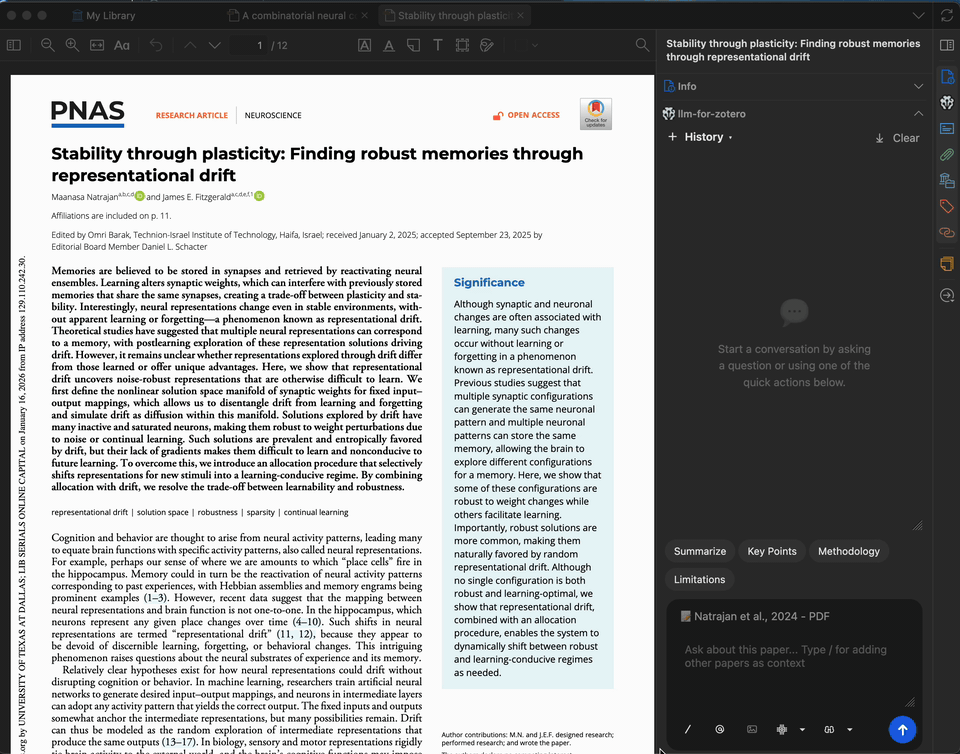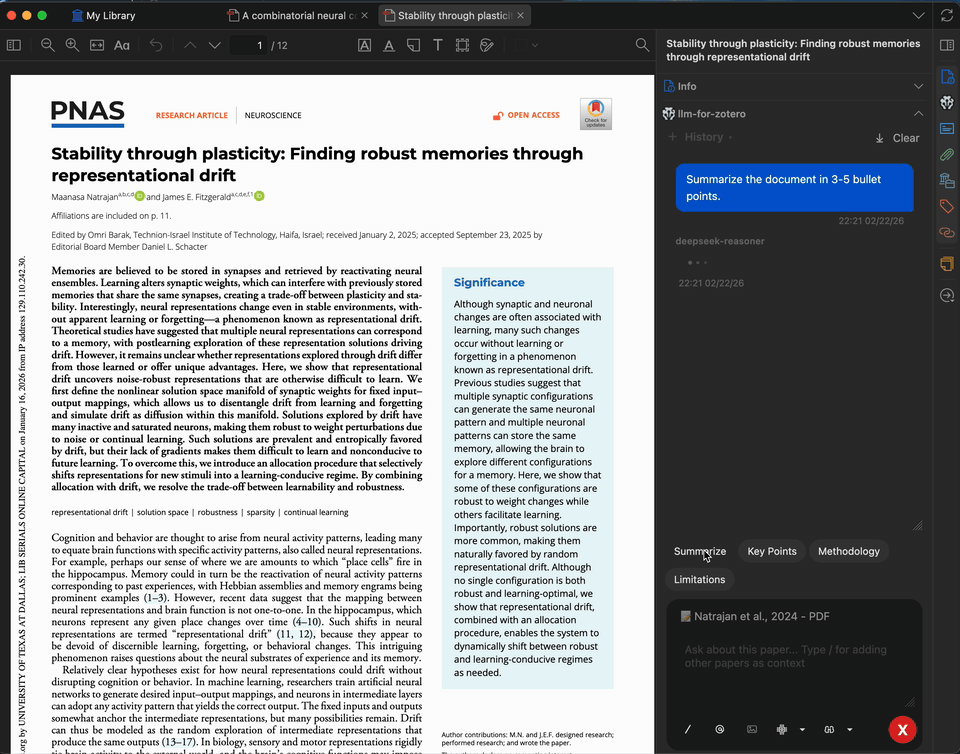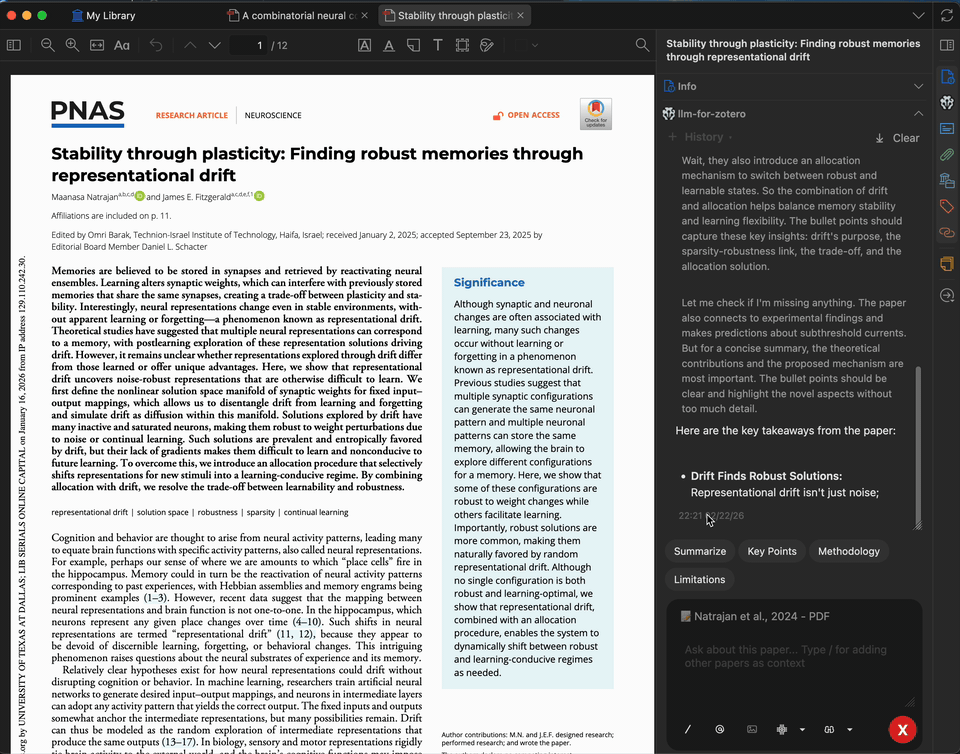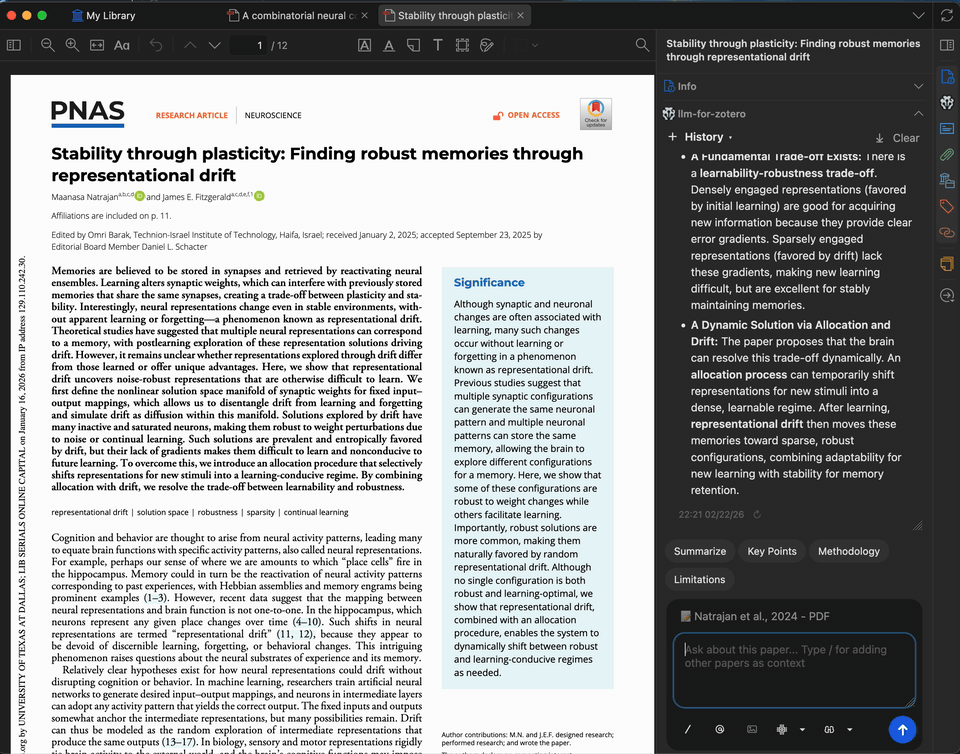
数秒内为任意论文生成简洁摘要。摘要基于完整 PDF 全文生成,您可以自定义提示词,聚焦于研究方法、结果、启示或其他任何方面。
选中文本解释
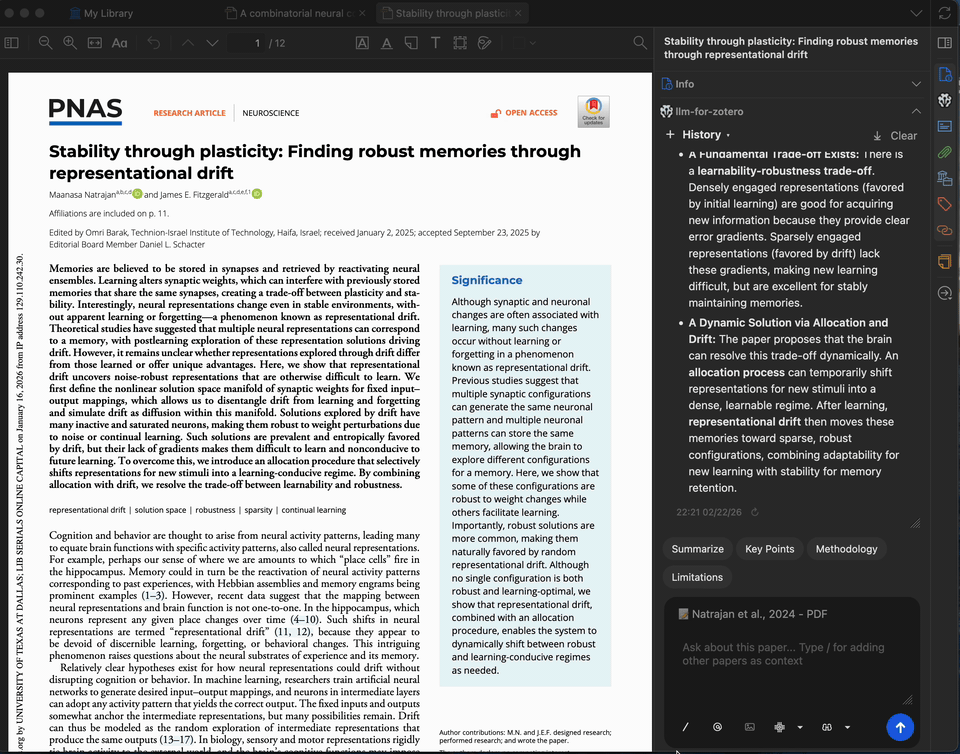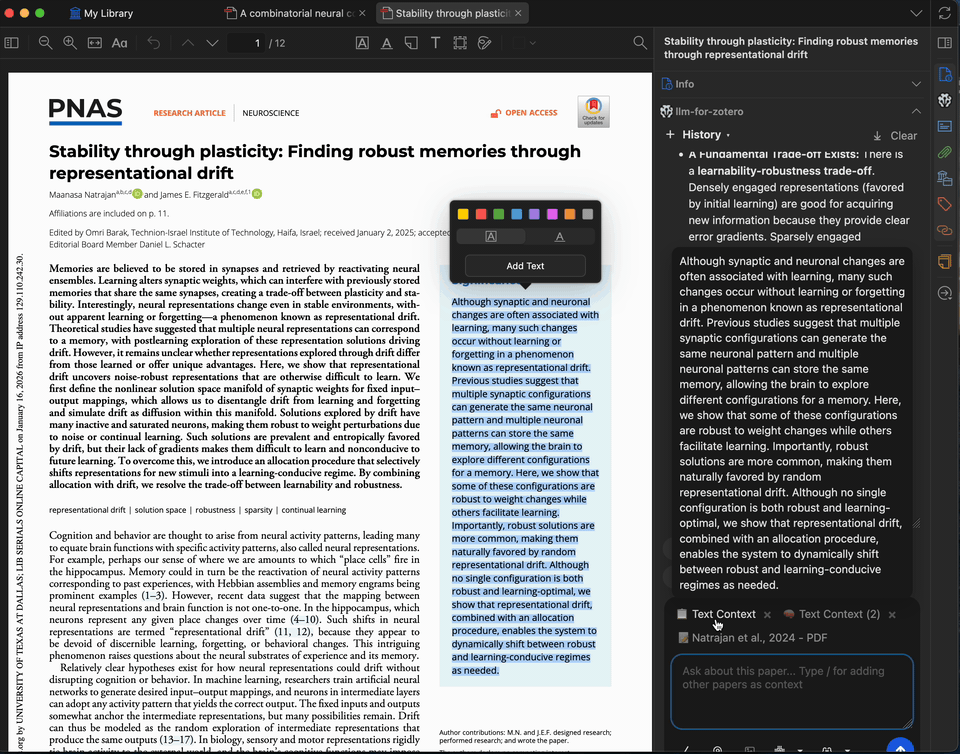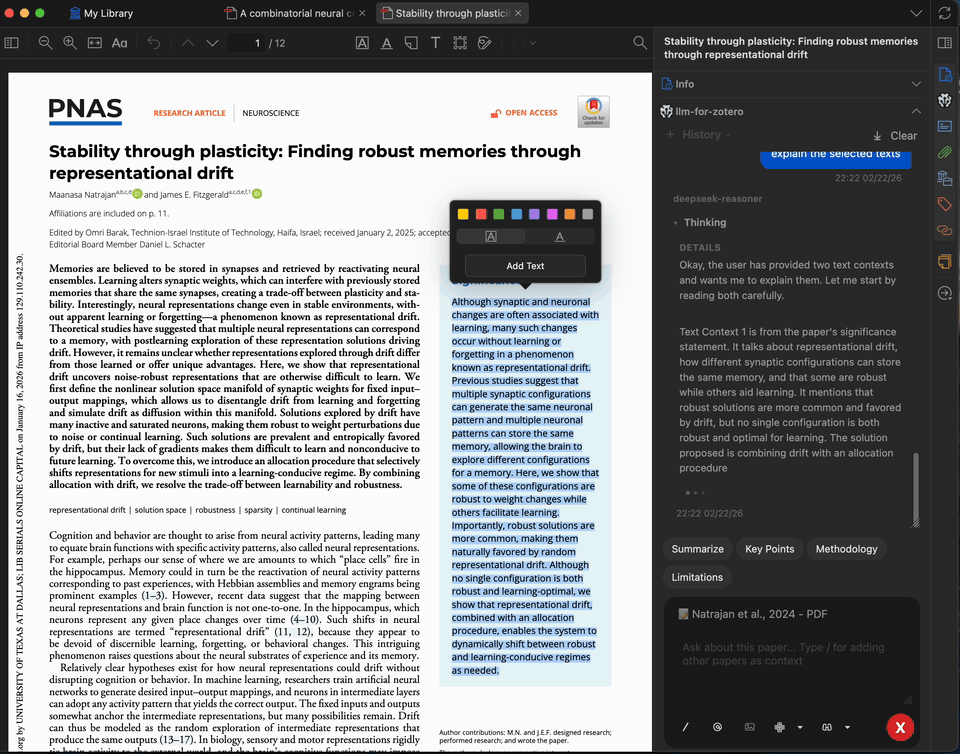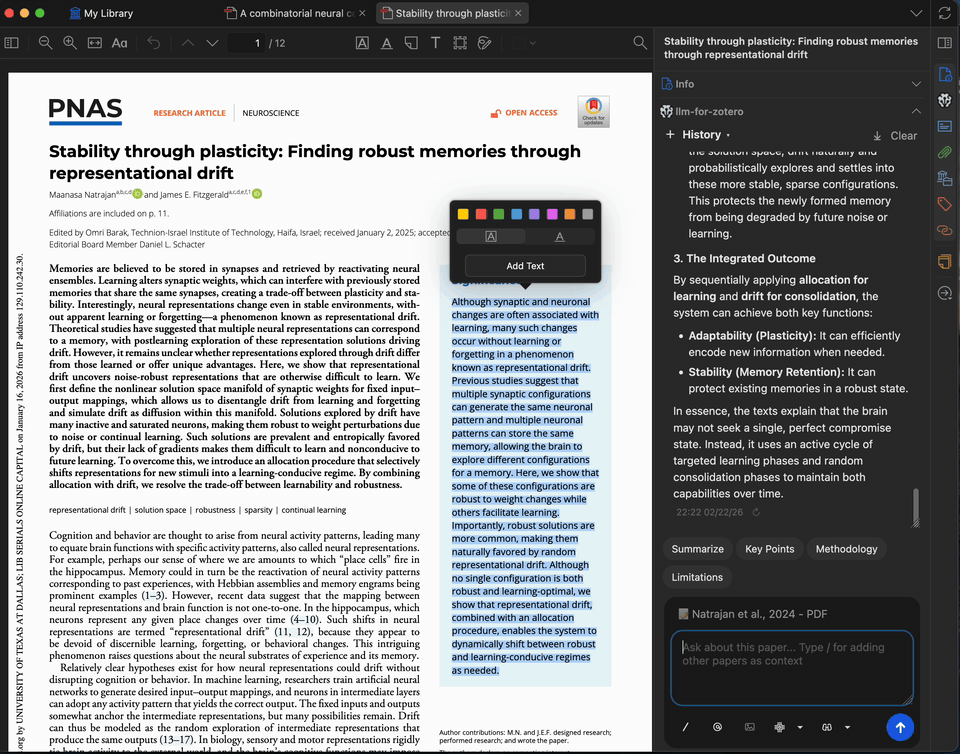
选中 PDF 中任意复杂段落或专业术语,请模型为其解释。您最多可添加 5 条上下文(来自论文或之前的回答)以进一步细化解释。
可选弹窗会自动建议将选中文本添加到对话,不喜欢可在设置中关闭。
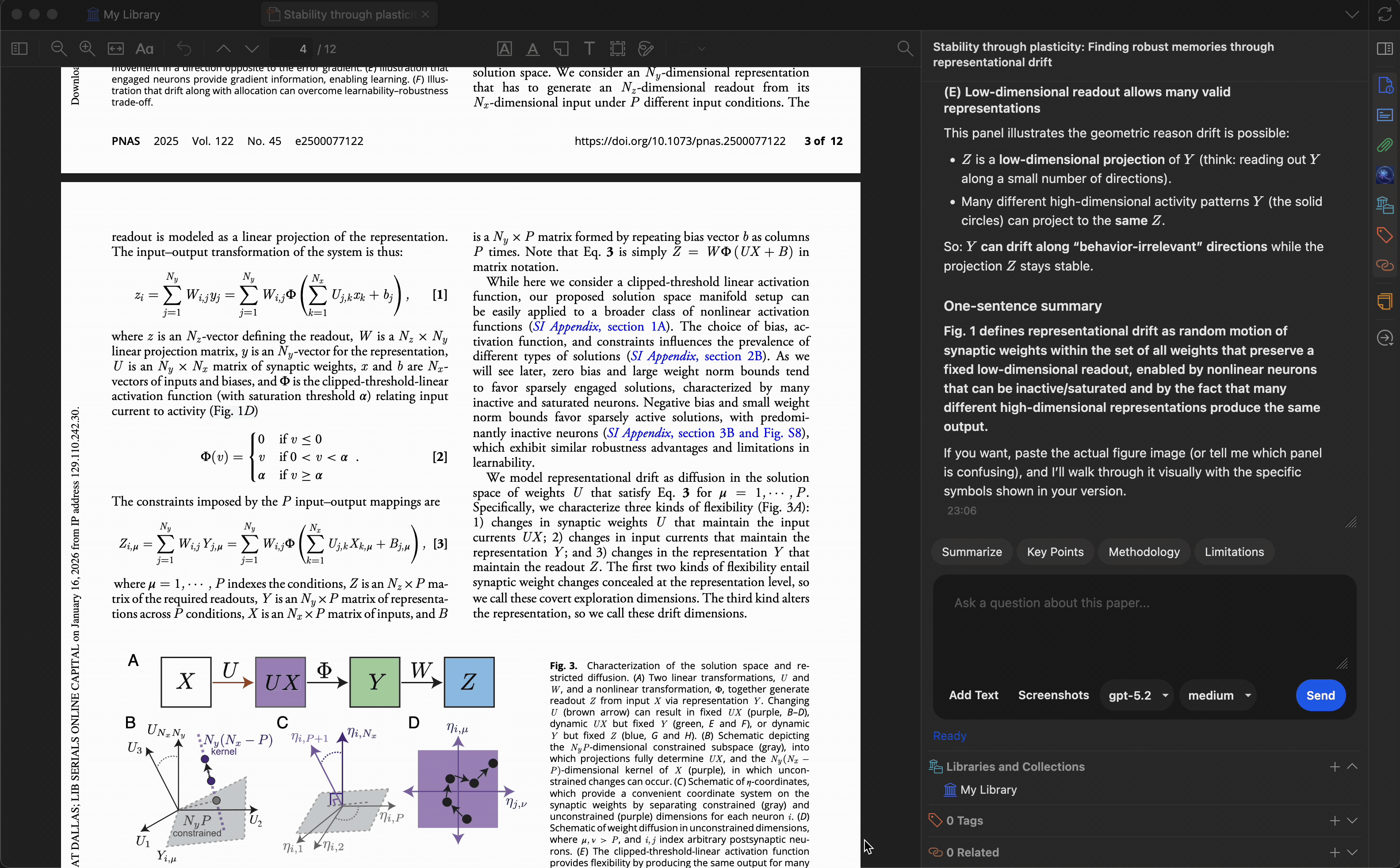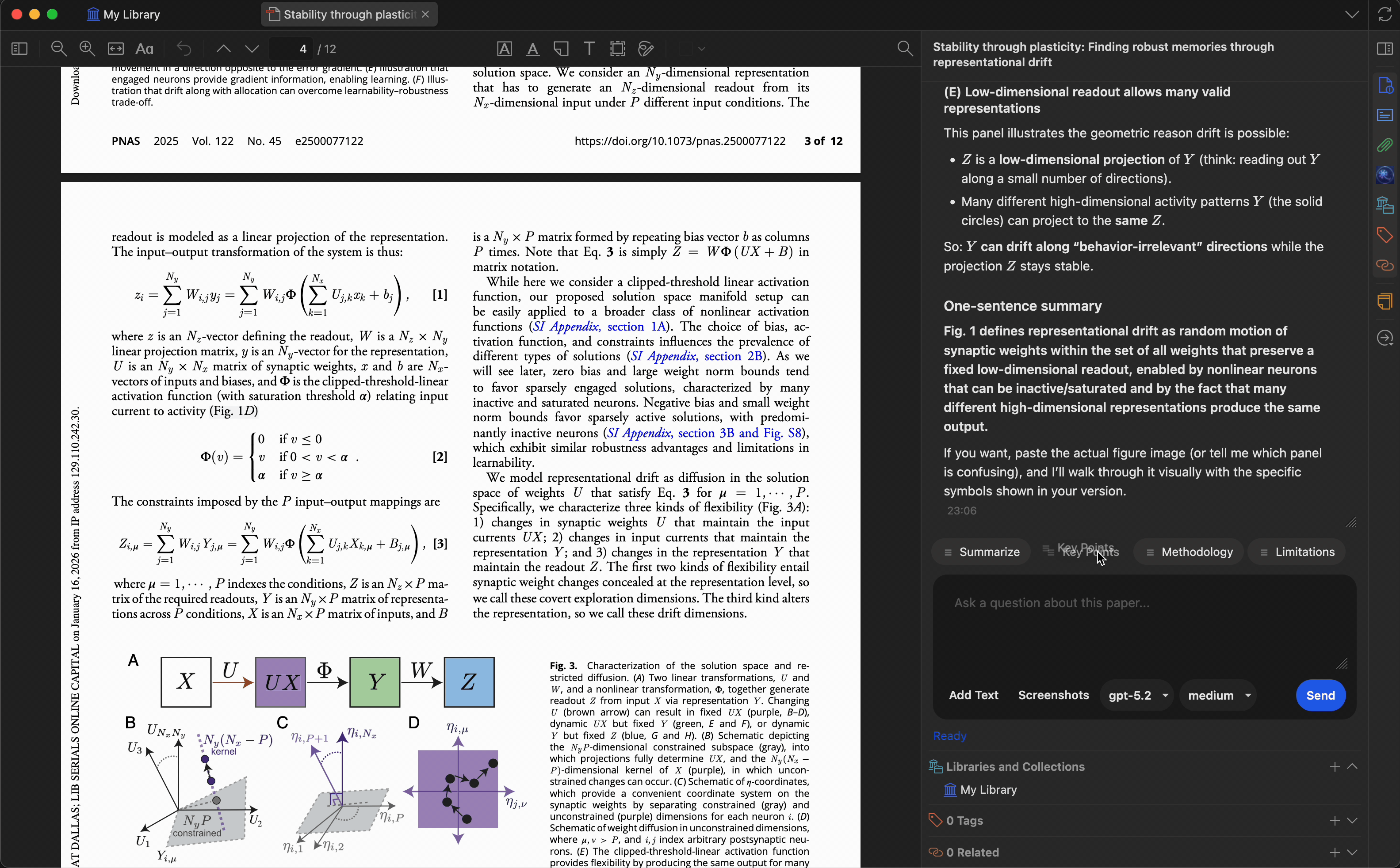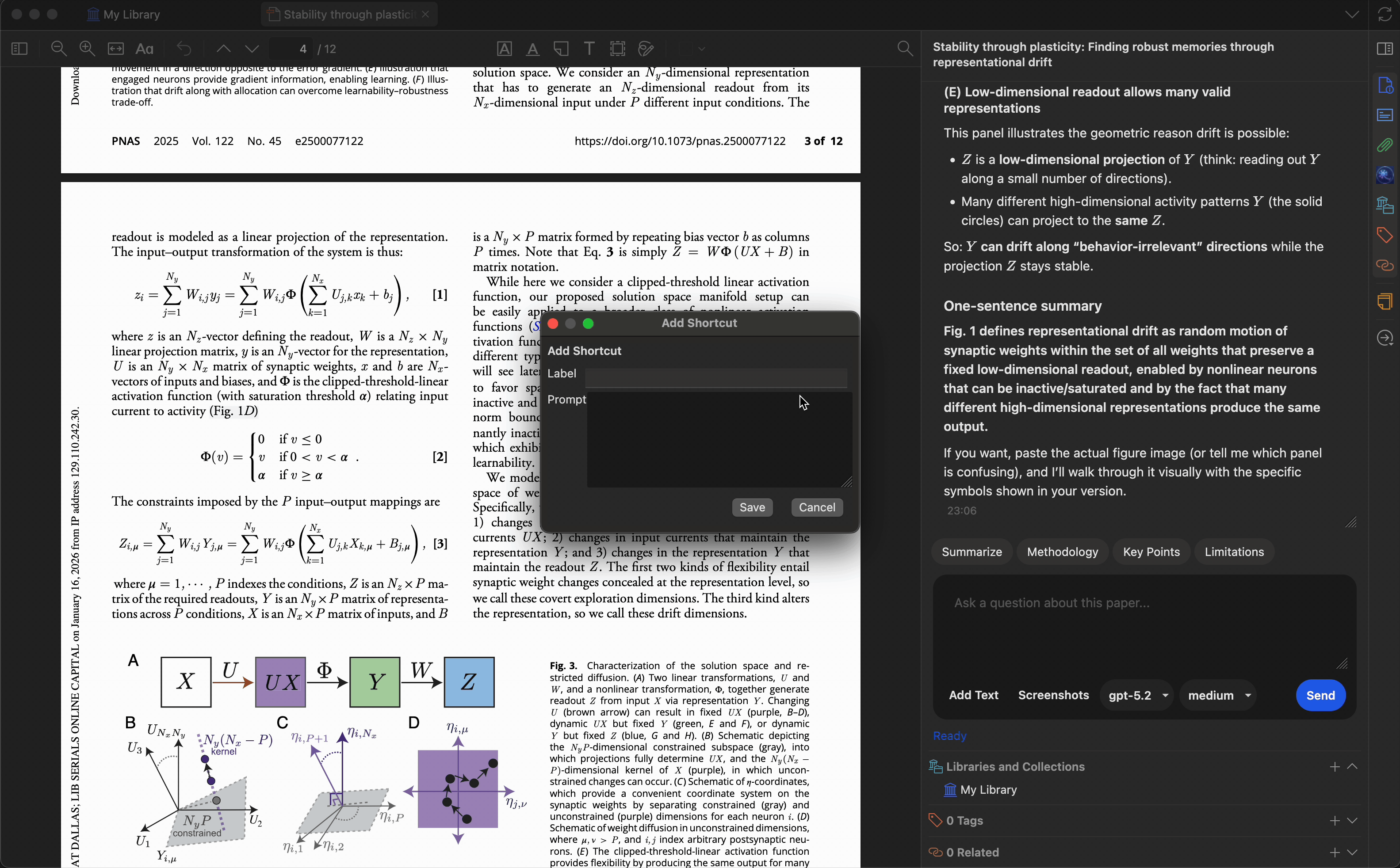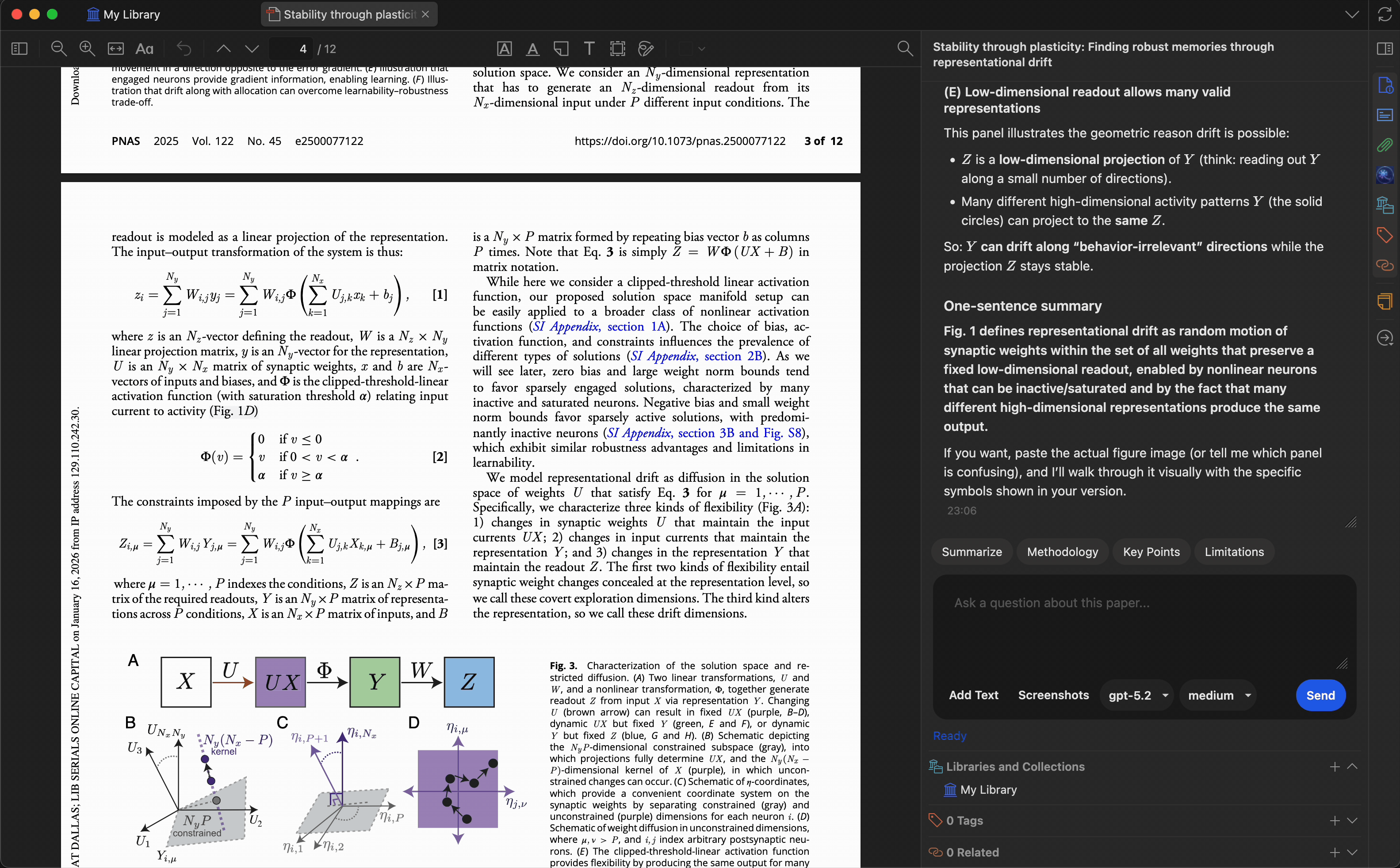
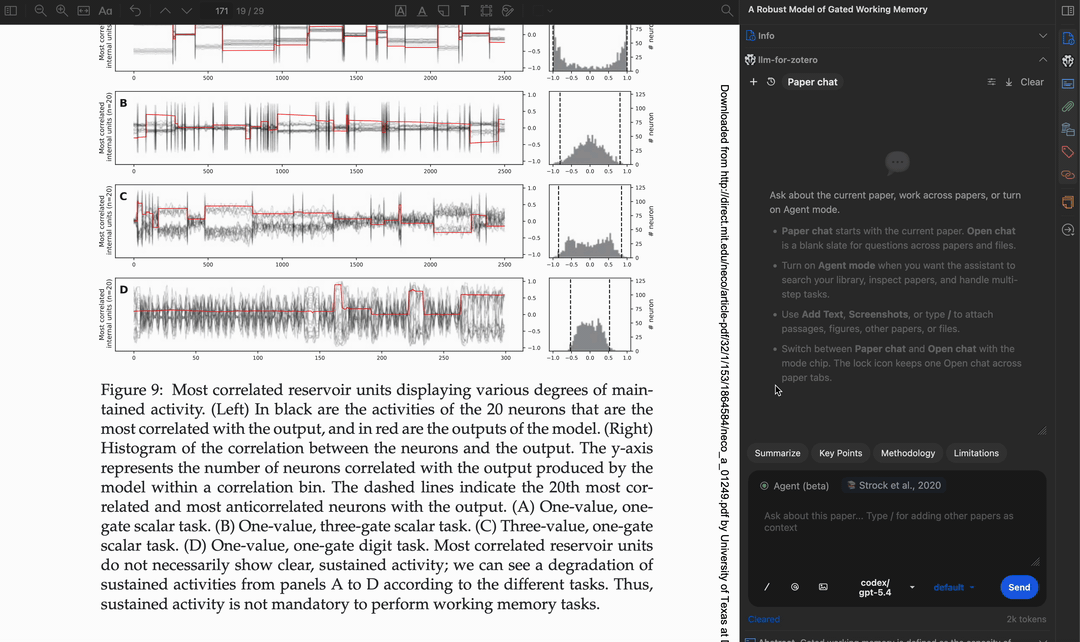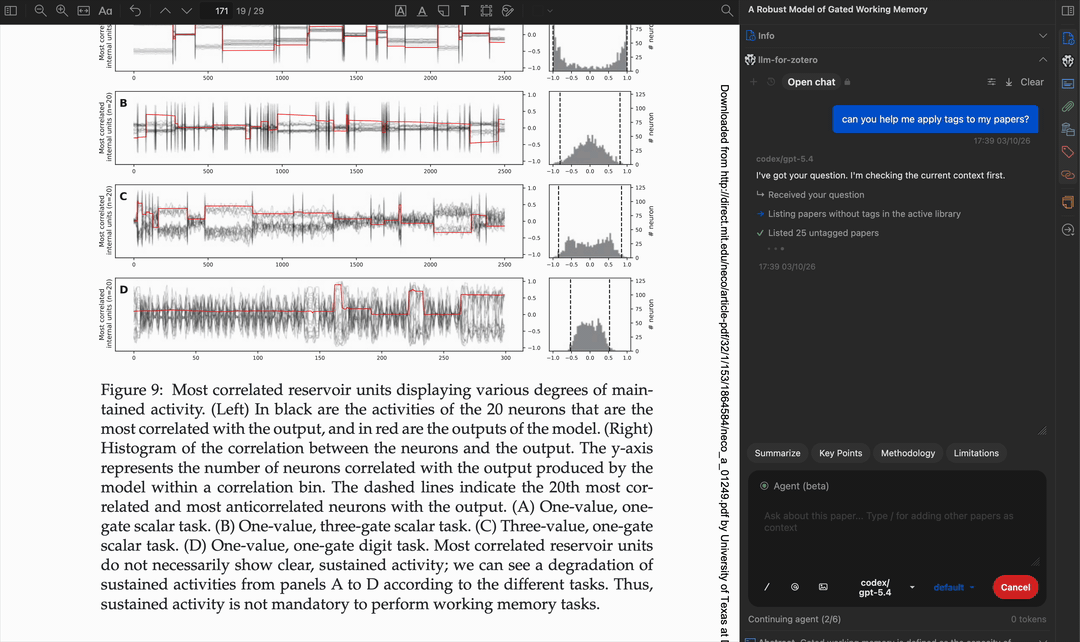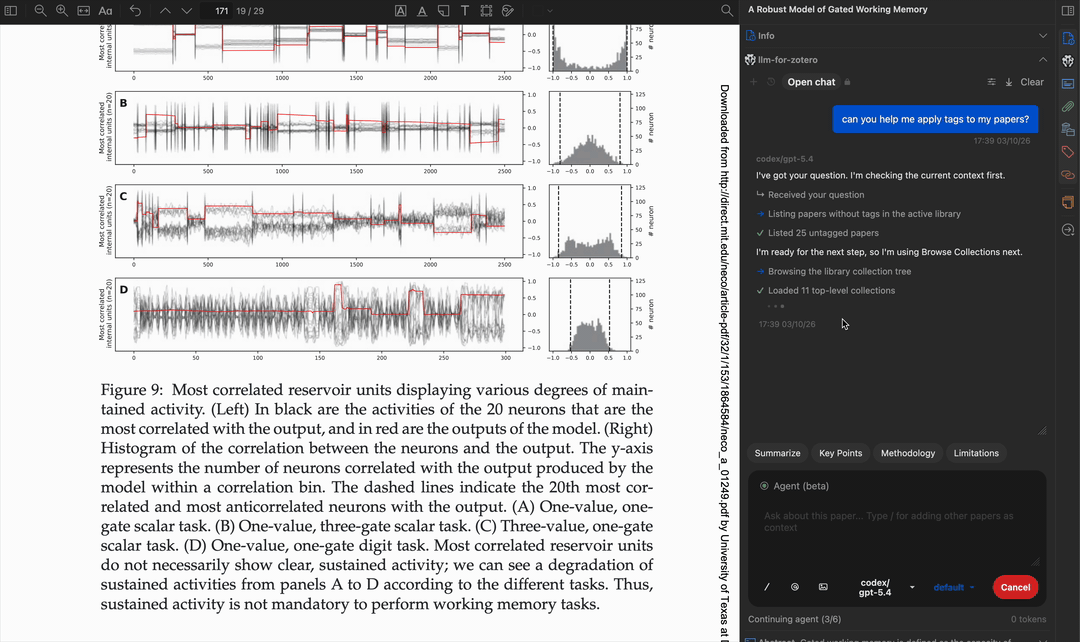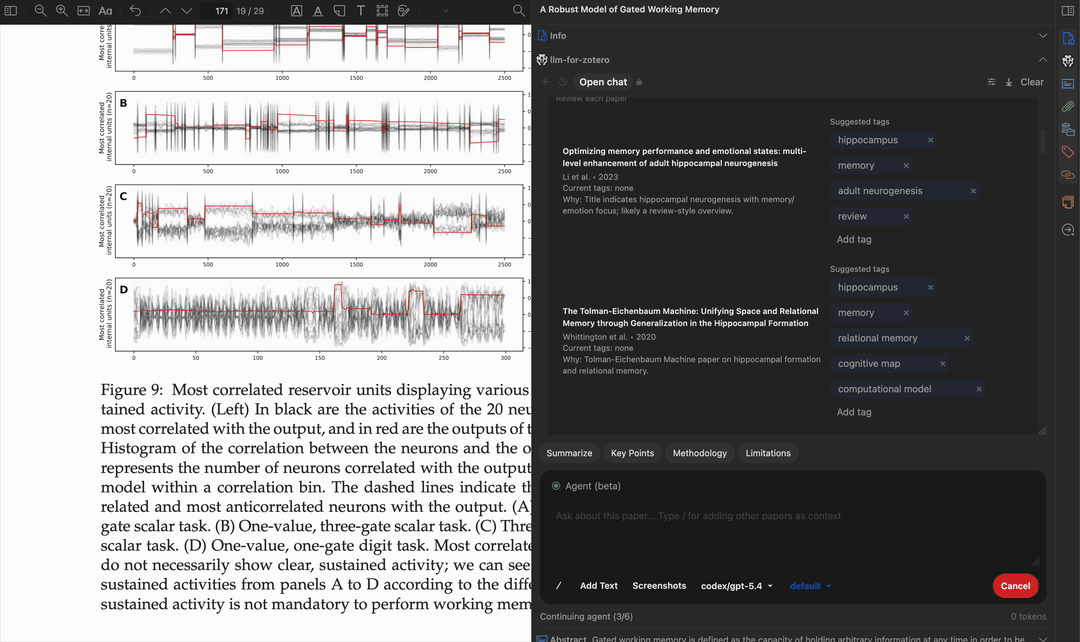
图表解读

截取任意图形、图表或示意图,请模型进行解读。每次最多支持 10 张截图,适合分析复杂的多面板图表或跨章节对比视觉内容。
跨论文对比

在不同标签页中打开多篇论文,并排对比。在输入框中输入 / 可引用其他已打开的论文作为额外上下文,单次对话最多可引用 10 篇论文,实现深度跨文献分析。
外部文档上传

从本地磁盘上传文档作为额外上下文,支持格式:
- PDF(每个文件最大 50 MB)
- DOCX(Word 文档)
- PPTX(PowerPoint 演示文稿)
- TXT(纯文本)
- Markdown(.md 文件)
保存至笔记

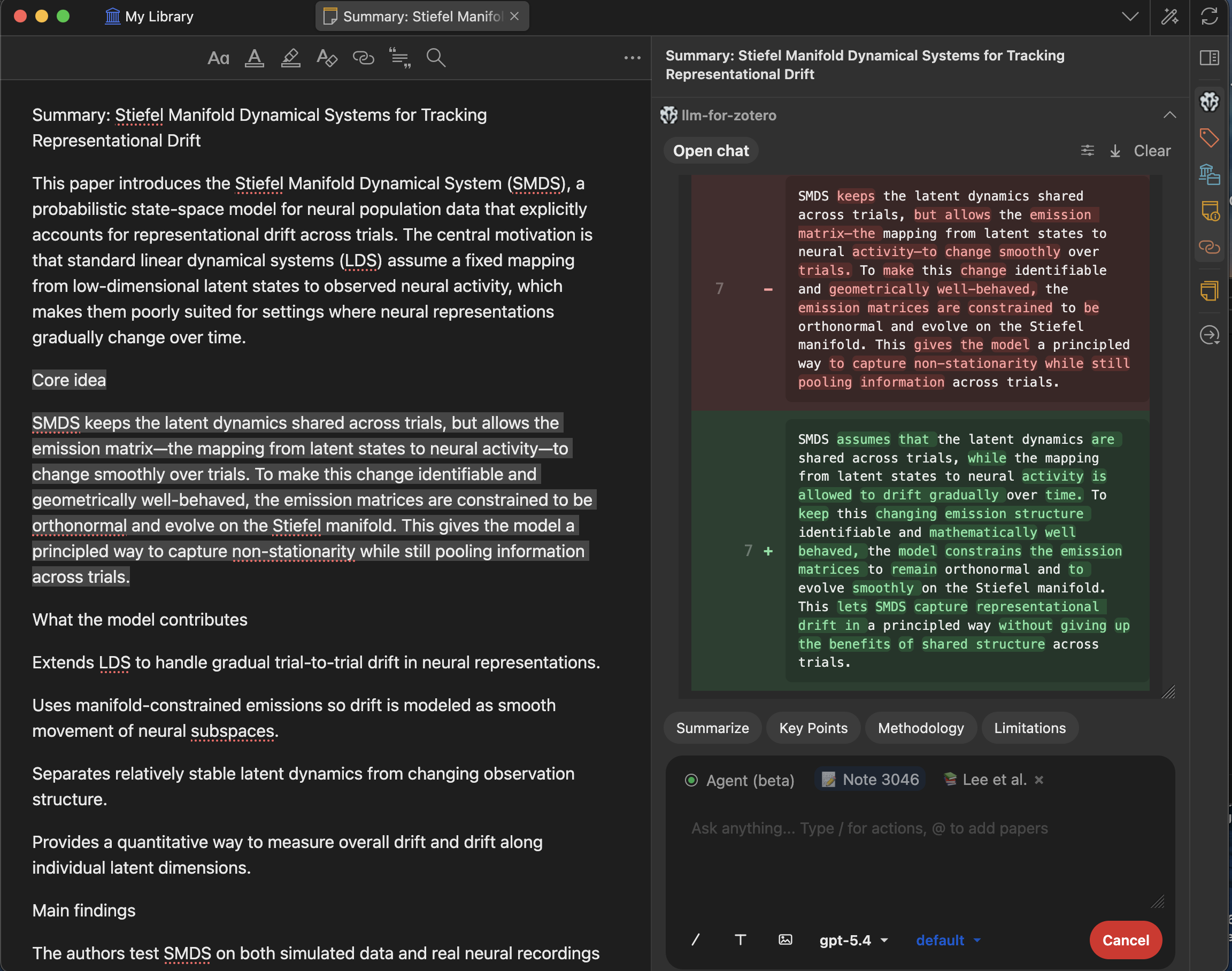
一键将任意回答或选中文本直接保存到 Zotero 笔记,与您现有的笔记工作流无缝集成,无需手动复制粘贴。
对话历史与导出

对话会自动保存到本地并与对应论文关联。您可以:
- 在历史记录面板中浏览过往对话。
- 将完整对话以 Markdown 格式导出到 Zotero 笔记。
- 导出内容包含选中文本、截图,以及正确渲染的 LaTeX 数学公式。
自定义快捷预设
创建最多 10 个自定义预设,将常用提示词一键触发。内置预设包括:
- 总结 — 生成简洁摘要
- 关键要点 — 提取主要发现
- 研究方法 — 描述研究方法
- 局限性 — 识别不足或局限
您可以修改这些预设或添加自定义内容,以适配您的研究工作流。
Agent 模式(Beta)
启用后,LLM 将成为一个自主 Agent,不仅可在 Zotero 文库中执行读取、搜索和写入操作,还能执行终端命令并访问本地文件——如同 Zotero 内置的编程 Agent。采用人机协作设计——所有写入操作均需您明确审批后方可执行。
读取工具
这些工具让 Agent 浏览您的文库和在线学术资源,不会修改任何内容。
| 工具 | 说明 |
|---|---|
query_library |
搜索和列举 Zotero 条目、文集、相关论文及重复项。支持多种查询模式(列表、搜索、重复项、未归档、无标签),可按文集、PDF 状态和标签筛选 |
read_library |
读取结构化条目状态:元数据、笔记、注释、附件(所有类型)及文集归属 |
inspect_pdf |
高级 PDF 操作:读取前置内容、搜索页面、提取证据、渲染页面、捕获当前阅读器视图、读取特定片段或完整文档 |
search_literature_online |
搜索在线学术资源(OpenAlex、arXiv、EuropePMC)或获取外部元数据(CrossRef、Semantic Scholar)。模式:推荐、引用、被引、搜索、元数据 |
写入工具
所有写入工具均需人工确认后方可生效。
| 工具 | 说明 |
|---|---|
apply_tags |
为一篇或多篇论文添加或移除标签,支持批量操作 |
update_metadata |
更新条目的元数据字段(标题、作者、DOI、期刊、摘要等) |
move_to_collection |
在 Zotero 文集之间移动条目 |
manage_collections |
创建或删除文集(文件夹),支持嵌套 |
edit_current_note |
创建或编辑 Zotero 笔记,支持导入本地图片 |
import_identifiers |
通过 DOI、arXiv ID 或其他标识符导入论文——Zotero 自动获取元数据 |
import_local_files |
从文件系统导入本地文件(PDF、文档等)到 Zotero |
manage_attachments |
添加或移除条目上的附件(PDF、补充材料等) |
merge_items |
合并重复条目:保留主条目,将所有子项从重复项移入,然后将重复项移至回收站 |
trash_items |
将条目移至回收站 |
undo_last_action |
撤销上一次已审批的写入批次 |
终端与文件系统访问
Agent 包含两个系统级工具,使其成为可在 Zotero 内运行脚本和处理数据的编程 Agent。
| 工具 | 说明 |
|---|---|
run_command |
在本地机器上执行 Shell 命令(macOS 使用 zsh,Linux 使用 bash,Windows 使用 cmd.exe)。支持管道、重定向、通配符及所有 Shell 特性。每条命令超时限制 300 秒 |
file_io |
读写本地文件系统上的文件。支持 UTF-8 及其他编码 |
典型使用场景:
- 运行 Python 或 R 脚本分析从文库中提取的数据。
- 将元数据导出为 CSV/JSON 供外部处理。
- 调用命令行工具(如
pandoc、ffmpeg、pdftotext)作为 Agent 工作流的一部分。 - 动态编写并执行脚本,转换或可视化您的研究数据。
- 读取本地数据文件,并将结果写回 Zotero 笔记。
内置动作
Agent 为常见文库管理工作流提供高级动作,自动串联多个工具。
| 动作 | 功能说明 |
|---|---|
| 文库审计 | 扫描文库(或文集)中元数据不完整的条目——缺少摘要、DOI、标签或 PDF 附件。可选将报告保存为 Zotero 笔记 |
| 自动标签 | 查找所有无标签论文,打开批量标签分配对话框供您审阅 |
| 发现相关文献 | 通过推荐、参考文献或被引关系,从学术源中查找种子论文的相关论文 |
| 同步元数据 | 从外部源(CrossRef、Semantic Scholar)获取元数据并批量应用更新 |
| 整理未归档条目 | 查找未归档条目,通过交互式审阅流程将其归入文集 |
MCP 服务器
插件运行内置的 Model Context Protocol (MCP) 服务器,允许外部 AI Agent 和工具以编程方式与您的 Zotero 文库交互。
- 端点:
http://localhost:23119/llm-for-zotero/mcp - 协议:JSON-RPC 2.0(MCP v2024-11-05)
- 方法:
initialize、tools/list、tools/call
这意味着您可以将任何兼容 MCP 的 AI Agent(如 Claude Desktop、Cursor、自定义 Agent)连接到您的 Zotero 文库,使用上述所有工具。
Agent 演示
多步骤工作流
Agent 可以串联多个工具完成复杂任务——例如查找论文、读取元数据、搜索相关文献并撰写摘要笔记。
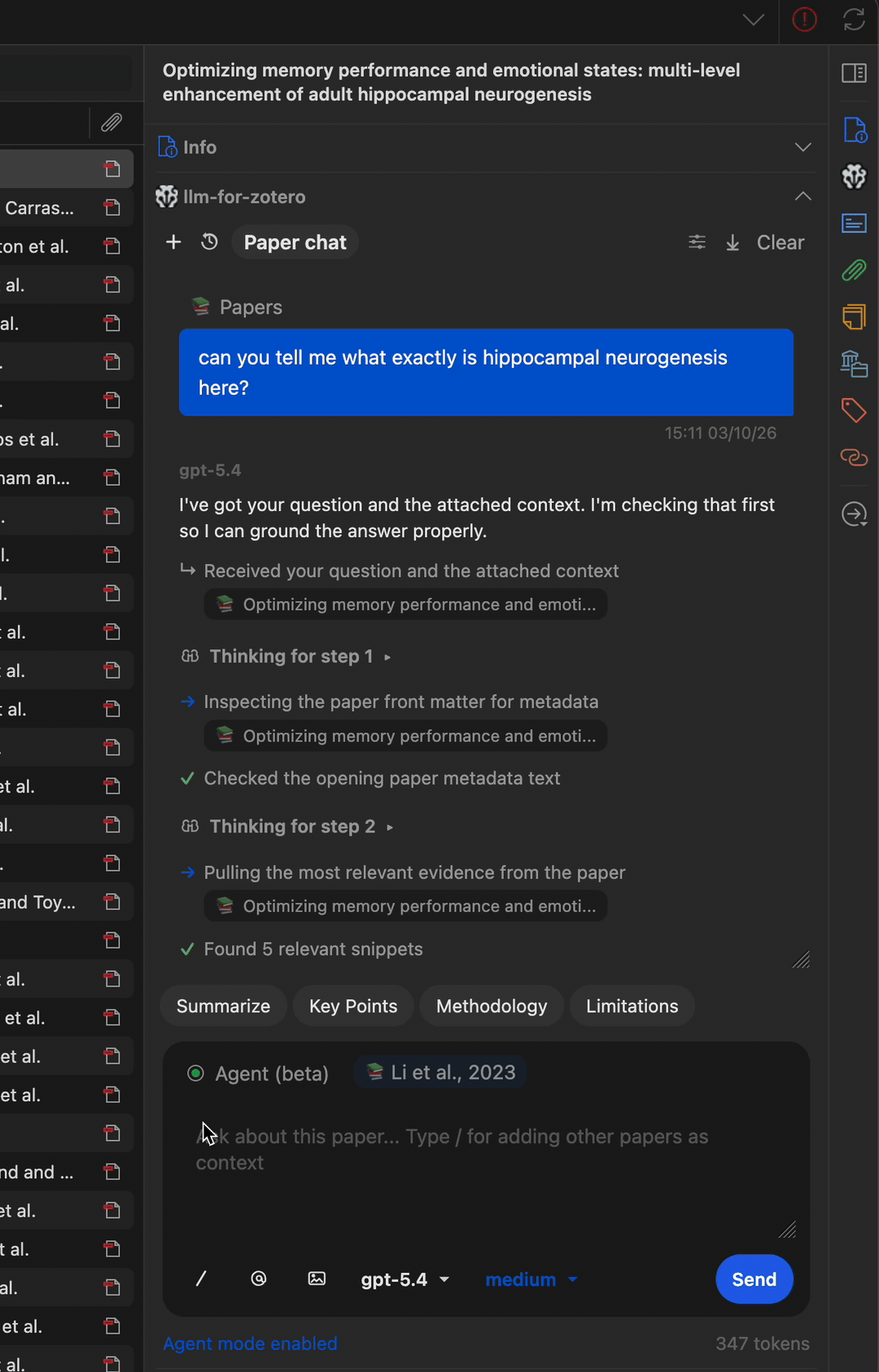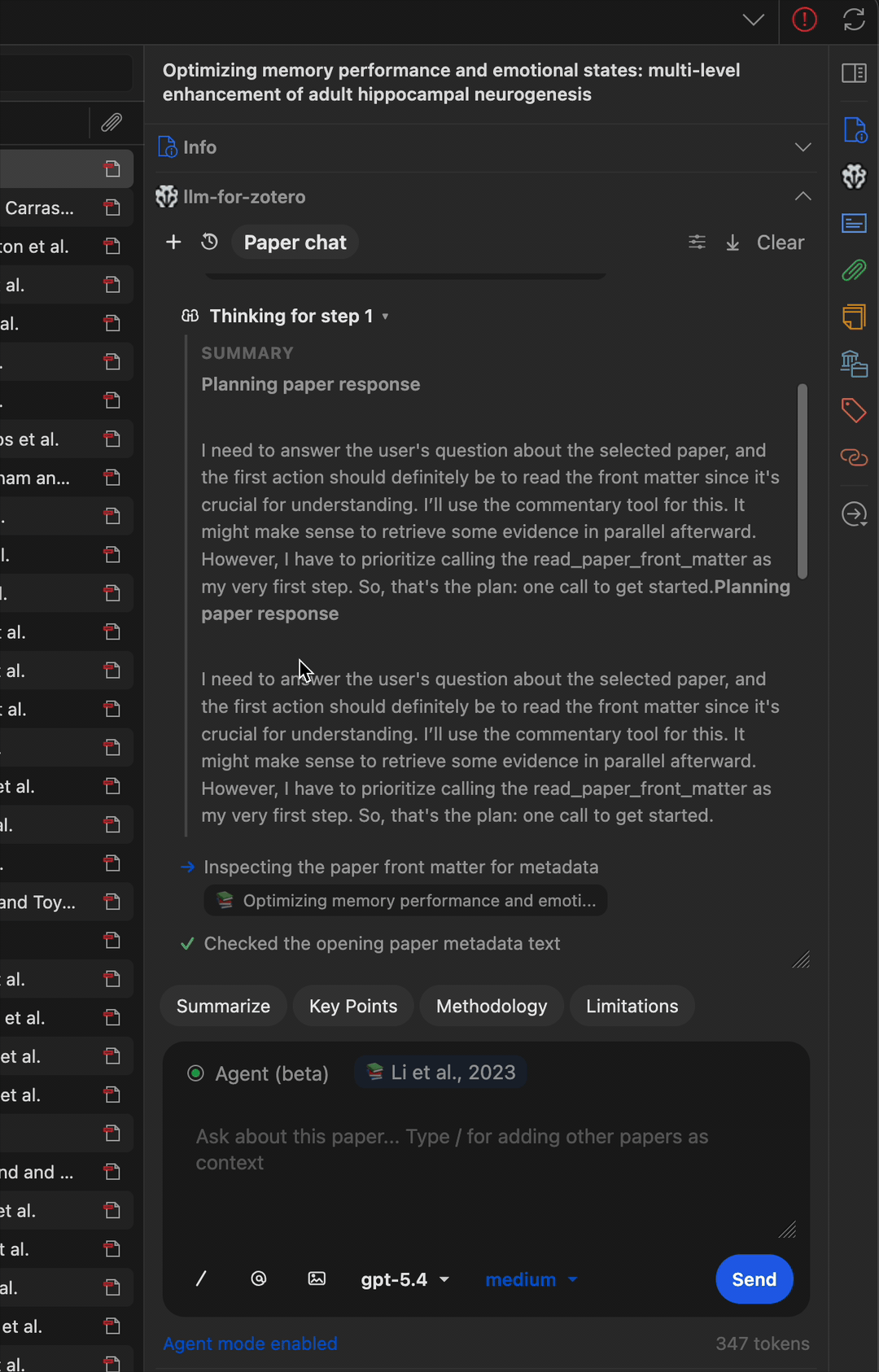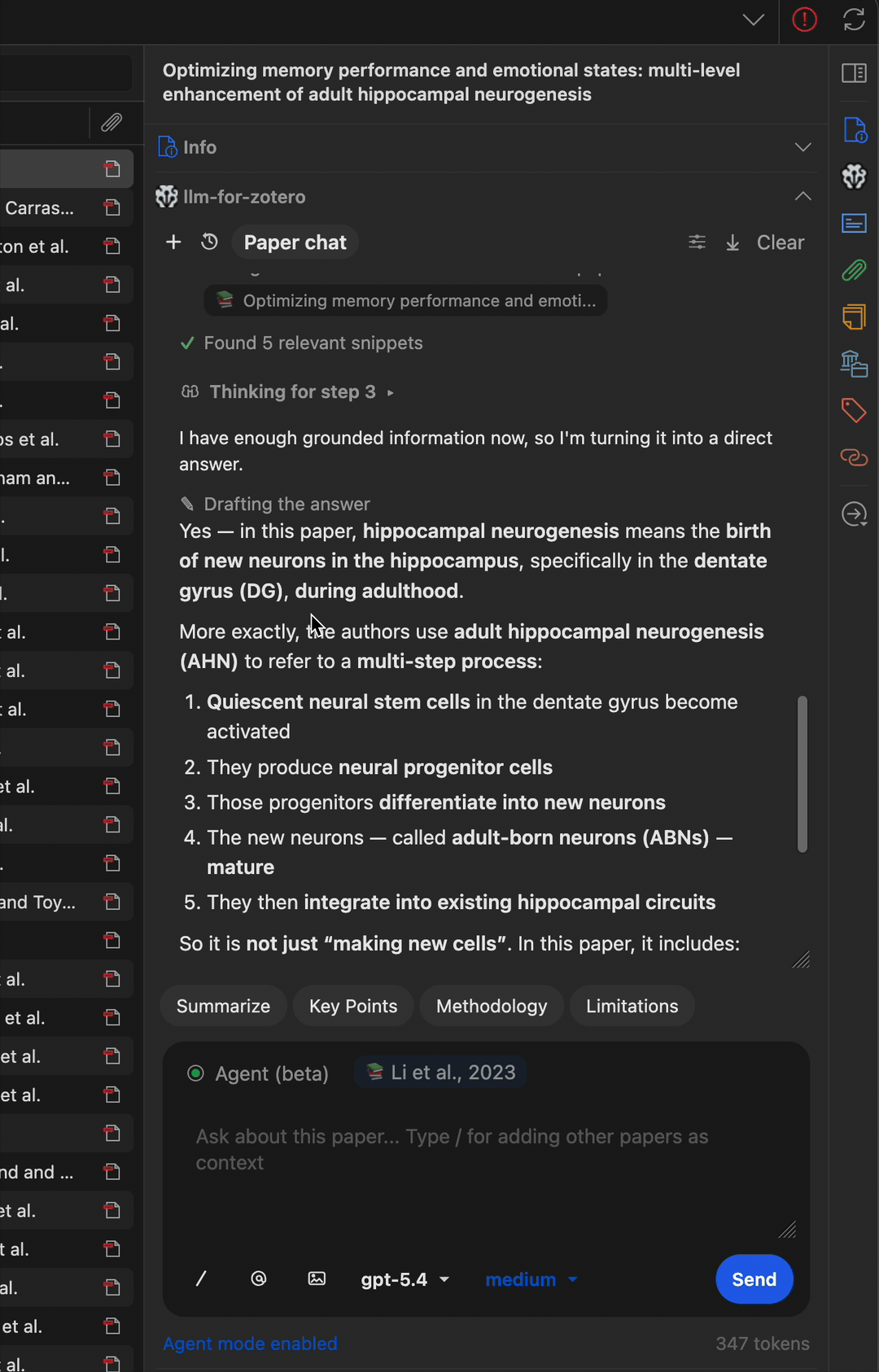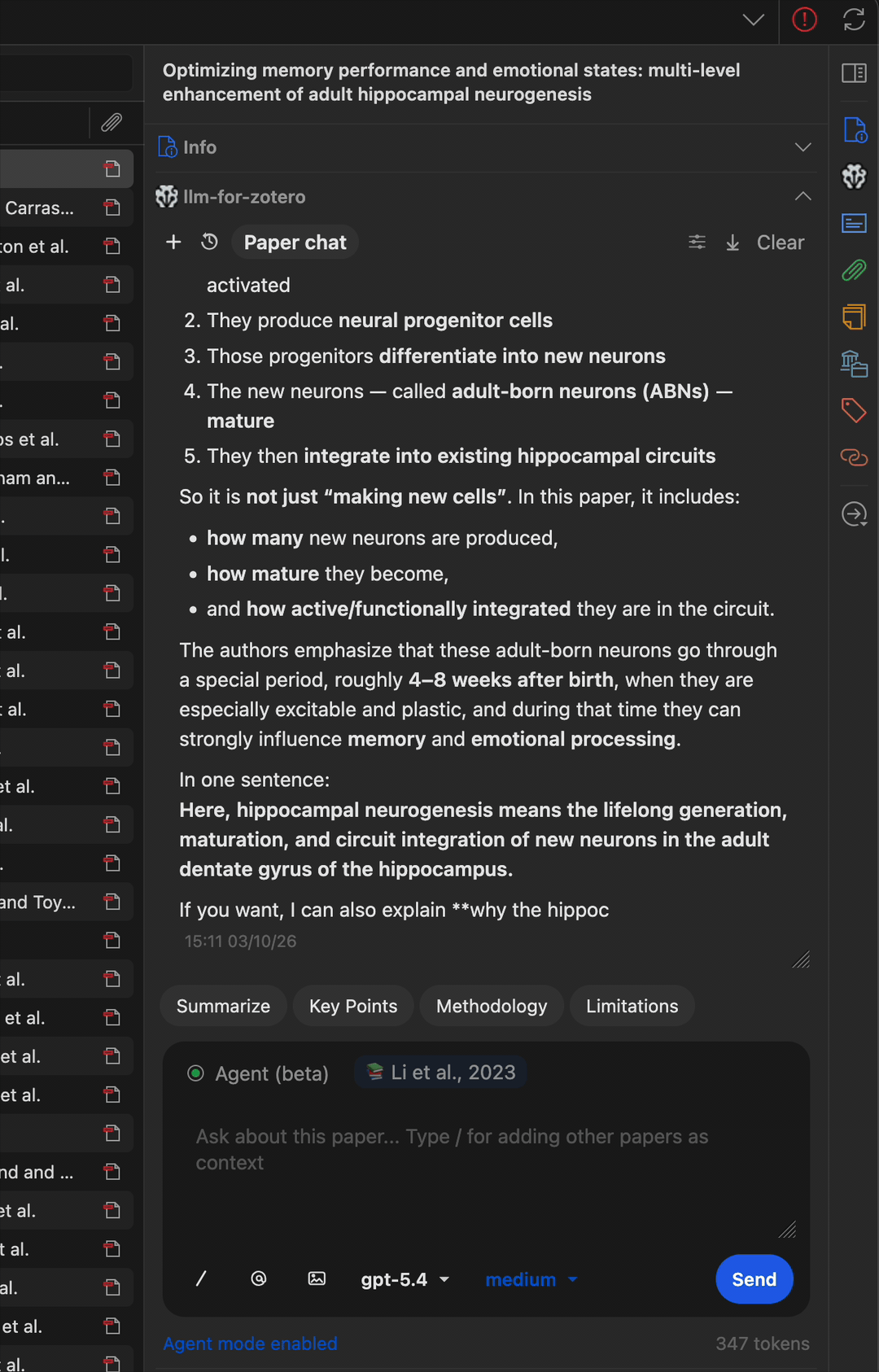
直接读取图表
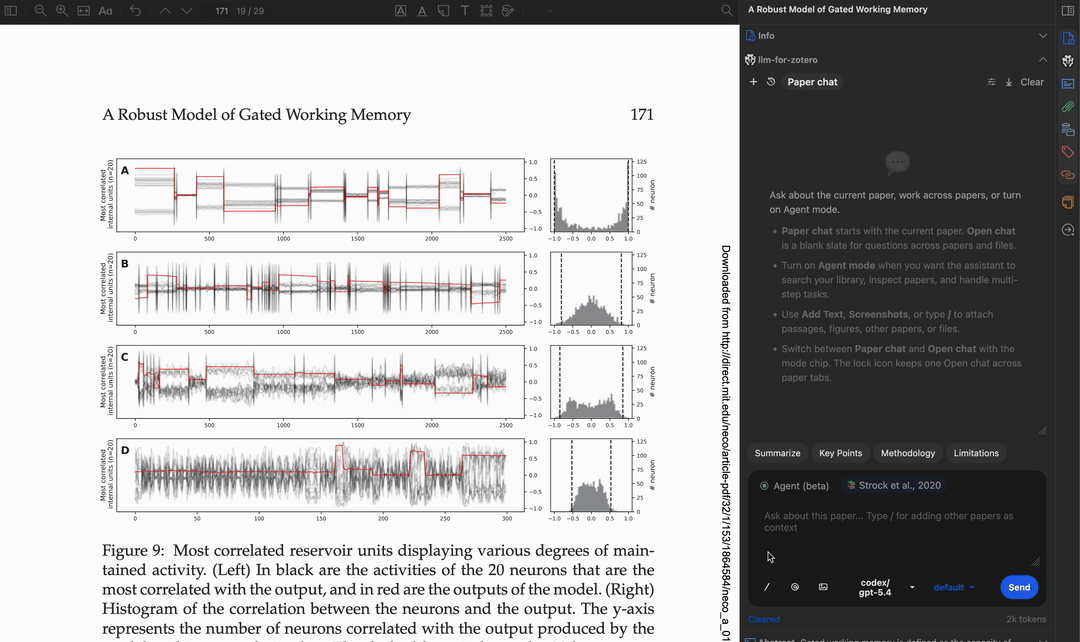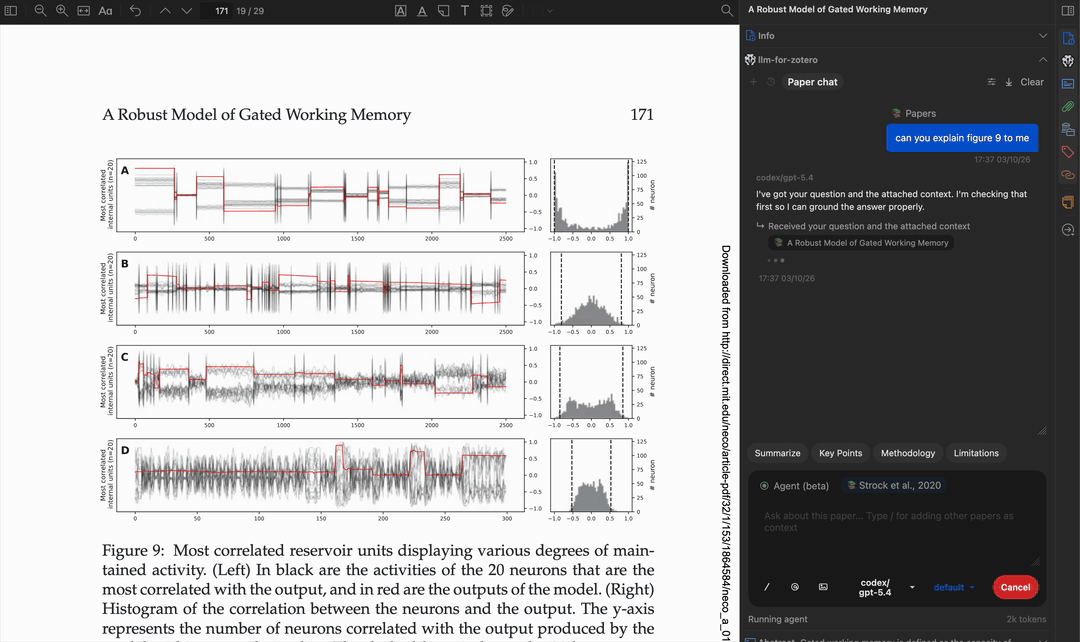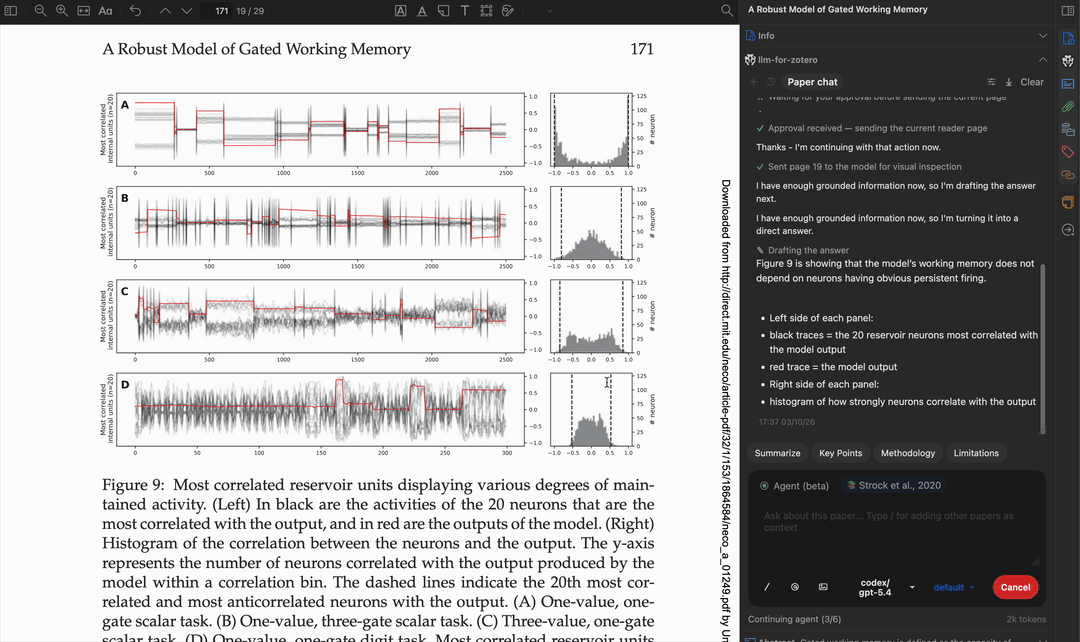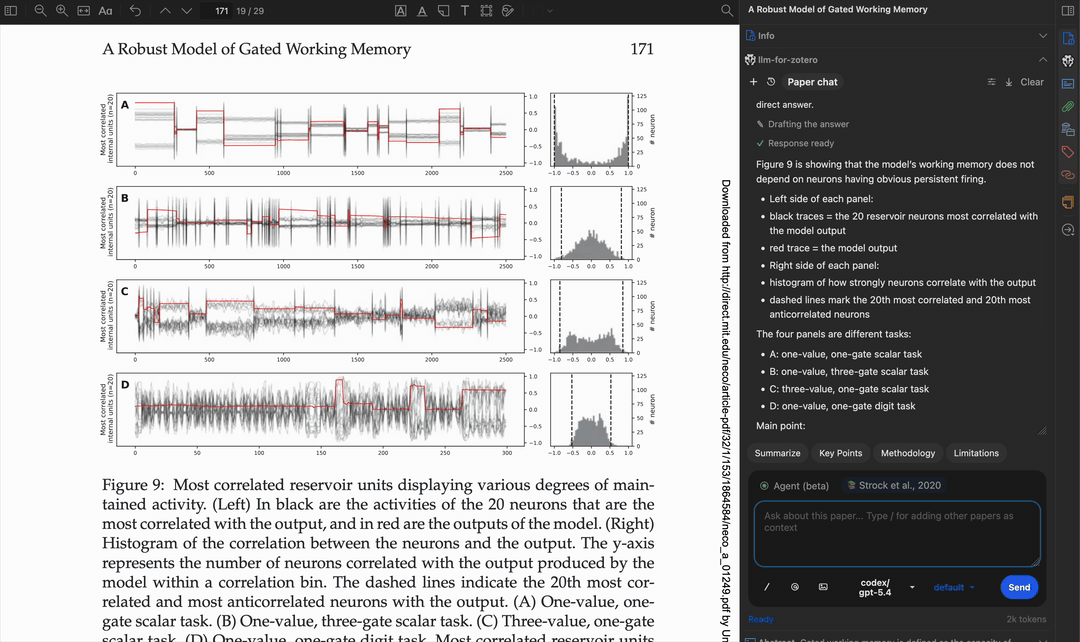
读取多页内容
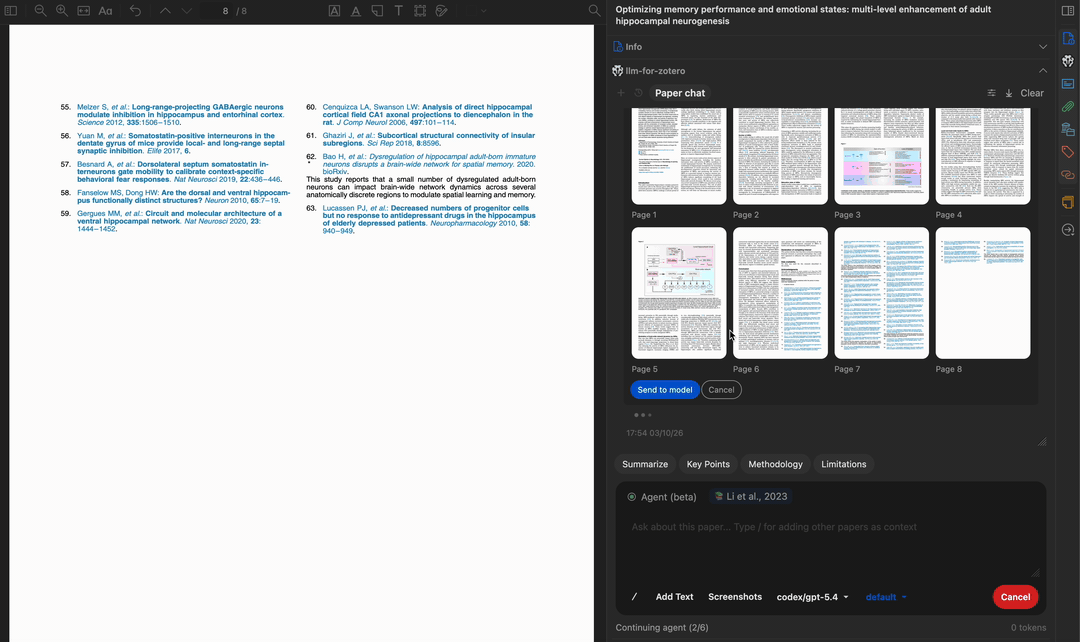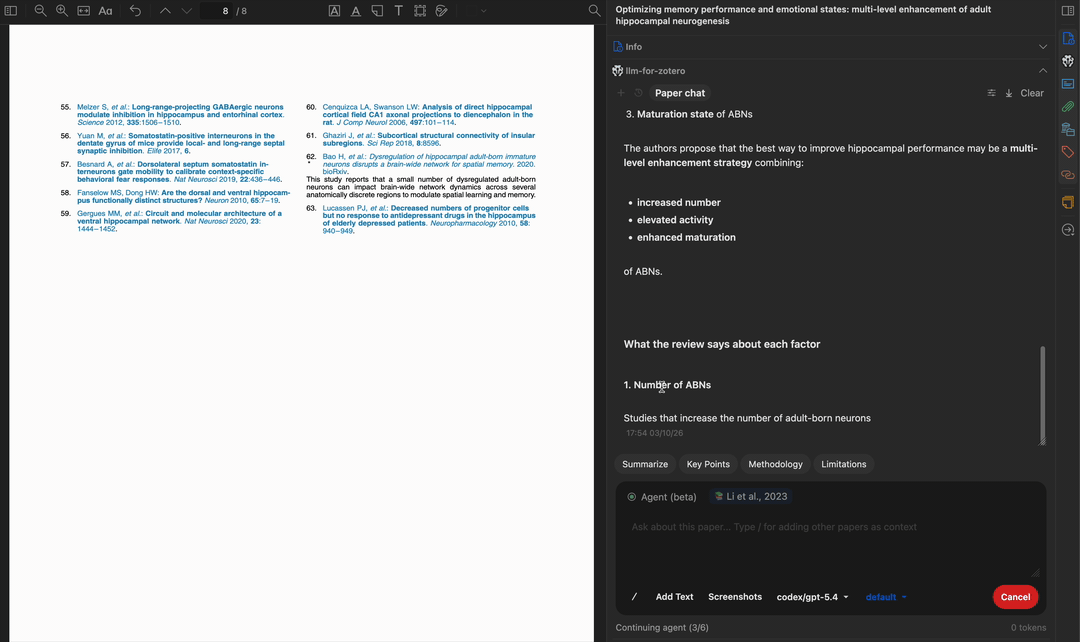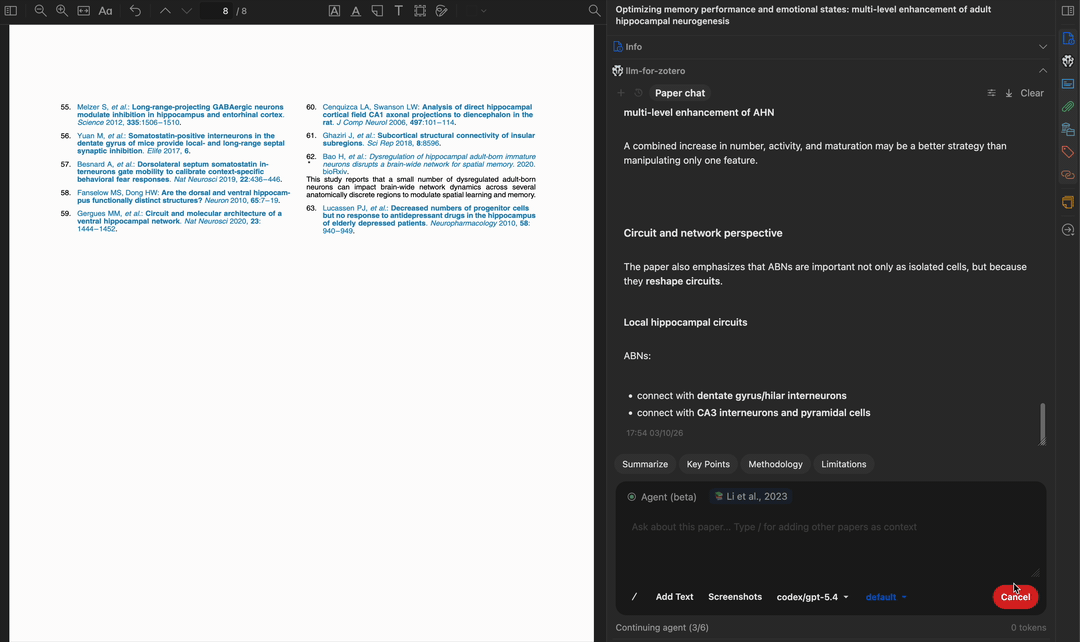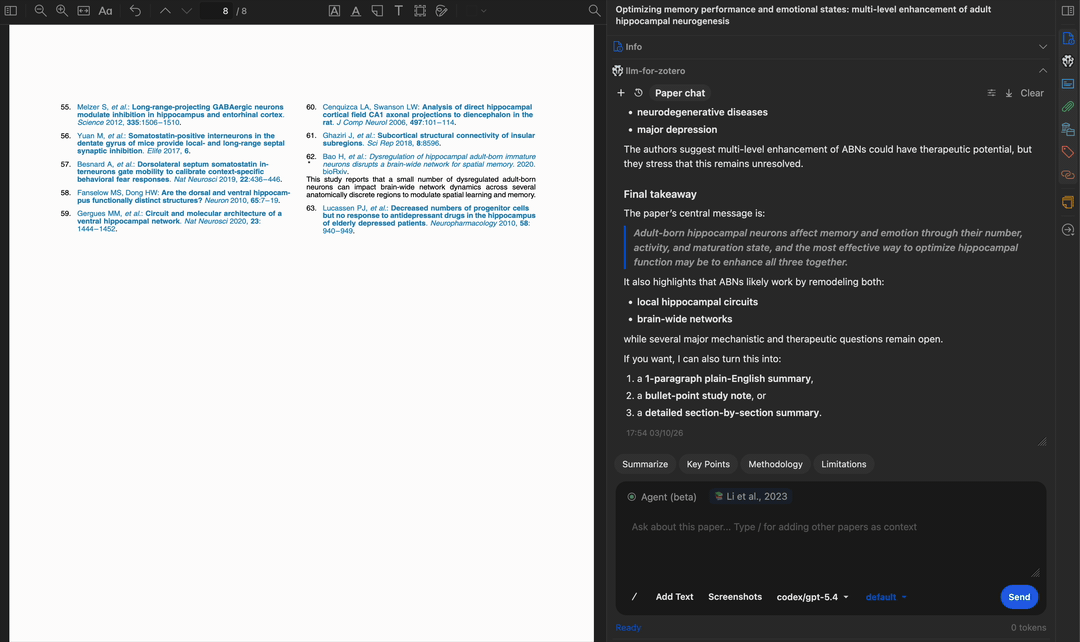
查找相关论文
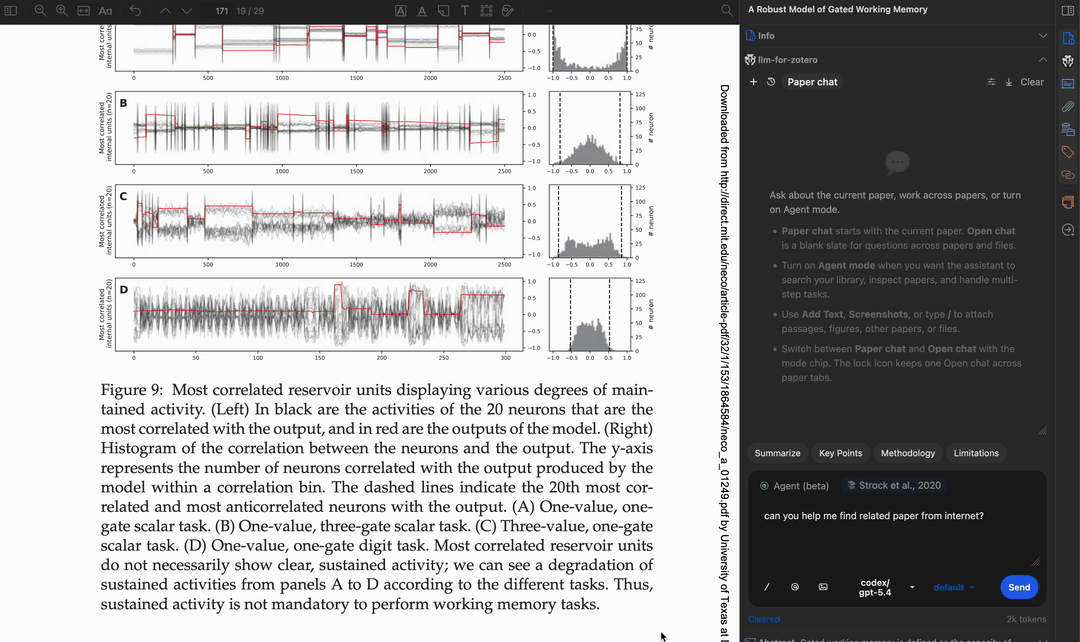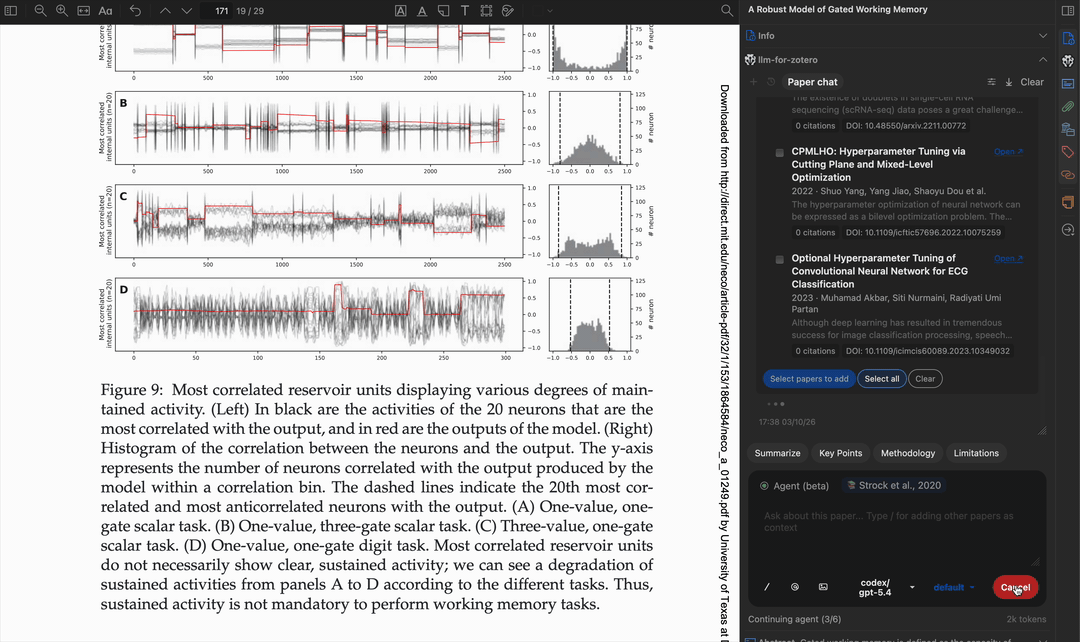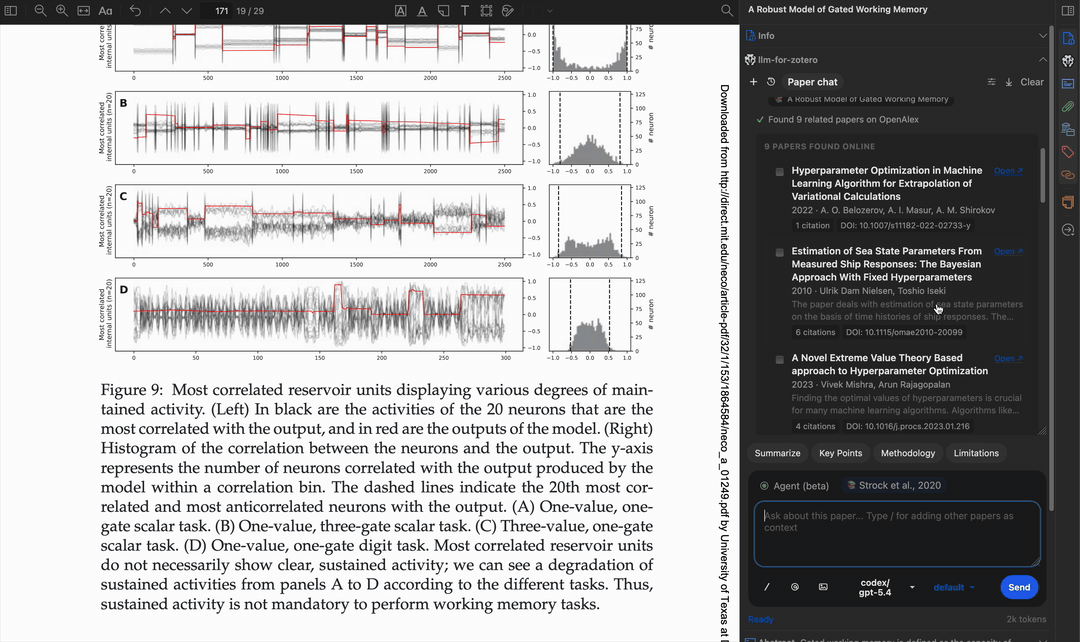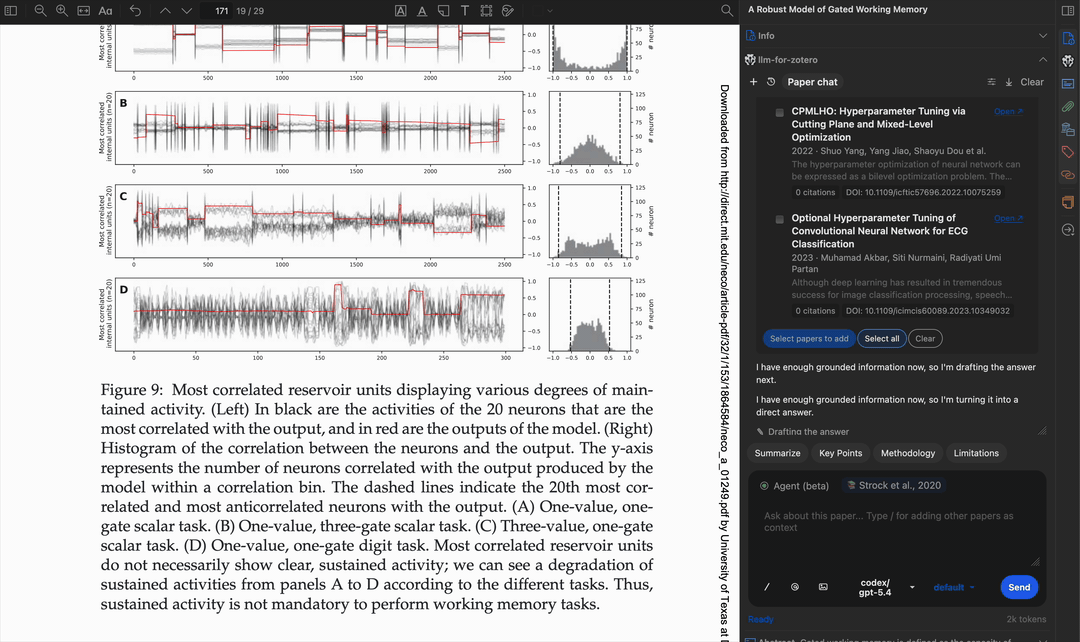
自动应用标签
撰写笔记
安全与审批
所有写入操作均通过人机协作确认流程:
- Agent 提出一批变更建议(如添加标签、编辑元数据)。
- 您在审批表单中查看拟定变更。
- 您可以在任何变更生效前选择批准、拒绝或修改。
- 如有问题,使用
undo_last_action进行撤销。 - 终端命令和文件操作同样需要明确审批后才会执行。
WebChat 配置(ChatGPT 网页同步)
WebChat 模式通过浏览器扩展将您的问题直接发送到 chatgpt.com——无需 API 密钥。查询从 Zotero 转发到 ChatGPT 网页界面,回复实时流式传回插件。
前置条件
- ChatGPT 账号(免费版、Plus 或 Team 均可)
- Chromium 内核浏览器(Chrome、Edge、Brave、Arc 等)
配置步骤
1. 下载浏览器扩展:
前往 github.com/yilewang/sync-for-zotero → Releases,下载最新的 sync-for-zotero-extension.zip,解压到电脑上的文件夹。
2. 安装扩展(侧载):
- 打开浏览器,访问
chrome://extensions - 开启右上角的开发者模式
- 点击加载已解压的扩展程序,选择解压后的扩展文件夹
- “Sync for Zotero” 扩展应出现在扩展列表中
3. 配置插件:
打开 Zotero → 首选项 → llm-for-zotero:
| 设置项 | 值 |
|---|---|
| 认证模式 | WebChat |
| 模型 | (自动设为 chatgpt.com) |
4. 开始对话:
在浏览器中打开一个 ChatGPT 标签页并保持打开。在 Zotero 中,插件面板会显示 “chatgpt.com” 指示器及连接状态点(绿色 = 已连接,红色 = 未检测到)。输入问题并发送即可。
WebChat 功能
- PDF 附件 — 右键点击论文标签切换 PDF 发送状态(紫色 = 发送,灰色 = 跳过)。
- 截图 — 使用截图按钮将图片上下文附加到消息中。
- 对话历史 — 点击时钟图标浏览和加载过往 ChatGPT 对话。
- 退出 — 点击 “Exit” 按钮返回常规 API 模式。
技术说明
- 插件在 Zotero 内置端口(23119)上嵌入轻量级 HTTP 中继服务器,浏览器扩展通过轮询该中继交换查询和响应。
- WebChat 模式下禁用 Agent 模式、斜杠命令(
/)和引用选择器(@)。 - 推理/思考模式在 ChatGPT 端控制,而非通过插件的推理切换按钮。
Codex 认证配置
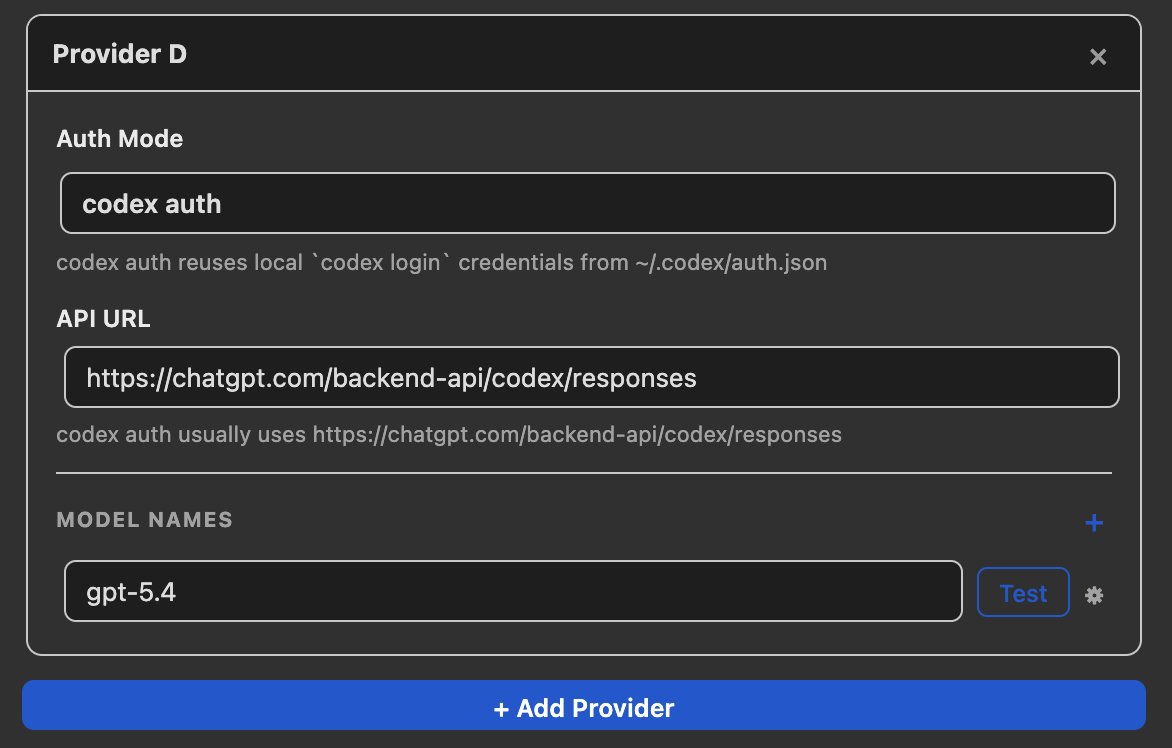
如果您拥有 ChatGPT Plus 订阅,可以使用 Codex 认证免 API 密钥访问 gpt-5.4 等模型。插件通过 Codex CLI 复用您的 ChatGPT 登录凭据。
配置步骤
1. 安装 Codex CLI(一次性操作):
# macOS / Linux(需要 Node.js 18+)
npm install -g @openai/codex
# macOS 替代方案(无需 Node.js)
brew install --cask codex
2. 登录 ChatGPT 账号:
codex login
浏览器窗口将自动打开——使用您的 ChatGPT Plus 账号登录。凭据保存至 ~/.codex/auth.json。
3. 配置插件:
在 Zotero → 首选项 → llm-for-zotero 中:
| 设置项 | 值 |
|---|---|
| 认证模式 | codex auth |
| API 地址 | https://chatgpt.com/backend-api/codex/responses |
| 模型 | 例如 gpt-5.4 |
点击测试连接以验证。
技术说明
- 从
~/.codex/auth.json(或$CODEX_HOME/auth.json)读取本地凭据。 - 遇到 401 响应时自动尝试刷新 Token。
- 支持本地 PDF 内容定位和截图/图像输入。
- Codex 认证模式暂不支持嵌入向量和
/files上传流程。
MinerU PDF 解析
MinerU 是一款先进的 PDF 解析引擎,可从 PDF 中提取高保真 Markdown,同时保留表格、公式、图表和复杂版式——这些内容在标准文本提取中往往会被破坏。
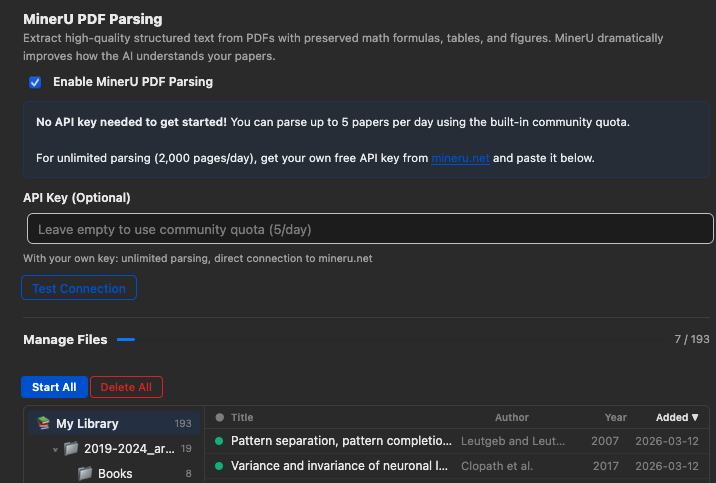
启用后,插件会将 PDF 发送到 MinerU API 进行解析并在本地缓存结果。此后与该论文的所有交互都将使用 MinerU 解析的内容,为模型提供更丰富、更准确的上下文。
启用方法
- 打开 Zotero → 首选项 → llm-for-zotero。
- 找到 MinerU 部分,勾选启用 MinerU。
- 可选填入您自己的 MinerU API 密钥。
- 打开任意 PDF 开始对话,插件会在首次使用时解析 PDF 并缓存结果。
使用自有 API 密钥
插件提供共享社区代理,开箱即用无需 API 密钥,但共享配额有限。如需更大用量:
- 前往 mineru.net 注册账号。
- 在账号设置中生成 API 密钥。
- 将密钥粘贴到 Zotero → 首选项 → llm-for-zotero → MinerU。
- 点击测试连接以验证。
提供个人 API 密钥后,插件将直接调用 https://mineru.net/api/v4。未提供密钥时,使用社区代理。
常见问题
是否免费使用?
是的,插件完全免费且开源(AGPL v3)。您只需为调用所选服务商的 API 付费。使用 Codex 认证时,ChatGPT Plus 订阅用户无需单独 API 密钥。
是否支持本地模型?
支持——任何提供 OpenAI 兼容 HTTP API 的模型均可使用,包括通过 Ollama、LM Studio、vLLM 等工具本地部署的模型。在设置中填写本地 API 地址和模型名称即可。
我的数据是否会用于训练模型?
不会。您使用自己的 API 密钥,数据隐私由您所选服务商的条款约束。大多数 API 服务商(如 OpenAI、Anthropic)不会将 API 数据用于模型训练。
能否同时使用多个模型?
可以。配置最多 10 个服务商组,每组包含多个模型,通过模型选择器在对话中随时切换。
上下文检索是如何工作的?
首条消息会加载论文全文作为上下文,后续问题使用混合检索(BM25 + 嵌入向量搜索)并结合多样性优化,定位最相关段落,保持响应快速准确。
如何报告 Bug 或提交功能请求?
请在 GitHub 上 提交 Issue。
贡献与支持
欢迎贡献!无论是 Bug 反馈、功能请求还是 Pull Request——欢迎在 GitHub 上提交 Issue 或 PR。
如果本插件对您有帮助,欢迎:
